We’re providing a summary of the board’s March 2026 meeting. At the meeting, the board reviewed progress in our key programs and initiatives, the strategic outlook for 2026, filled a vacancy on the Board, considered an additional legal entity for Crossref, and reviewed our governance structures. The resolutions are available on the dedicated section of our website, which also lists the members of the Board and offers further information about our governance.
In April 2025, we launched the metadata matching project, in order to add missing relationships to the scholarly metadata. We will do this by consolidating all existing and planned matching workflows, which enrich member-deposited metadata in Crossref. This unified service will result in a more complete research nexus. In this blog post, we share our latest milestone: developing and evaluating a strategy for matching funder metadata to Research Organization Registry (ROR) identifiers.
Preserving the integrity of the scholarly record is an important component of the overall endeavour to protect research integrity. Open scholarly infrastructure enables persistent recording of research objects and associated metadata, which provides an evidence trail for these objects for all in the research community. Crossref and DataCite – as providers of essential infrastructure for preservation of the scholarly record – we share our joint expertise in the new guide on “Why metadata matters for research integrity and how to contribute”.
As our global community continues to grow, it is important for us to build and maintain our connections within it. In March this year, we had the opportunity to visit São Paulo for a community event at the Fundação Getúlio Vargas. The content of our presentations is available online. Events such as this provide an opportunity for us to update our members on Crossref fundamentals and developments, and help us better tune in to the varied needs of our communities and learn how we can work together more effectively. This was our third visit to Brazil, with previous events held in Campinas and São Paulo in 2016, and Goiânia and Fortaleza in 2018.
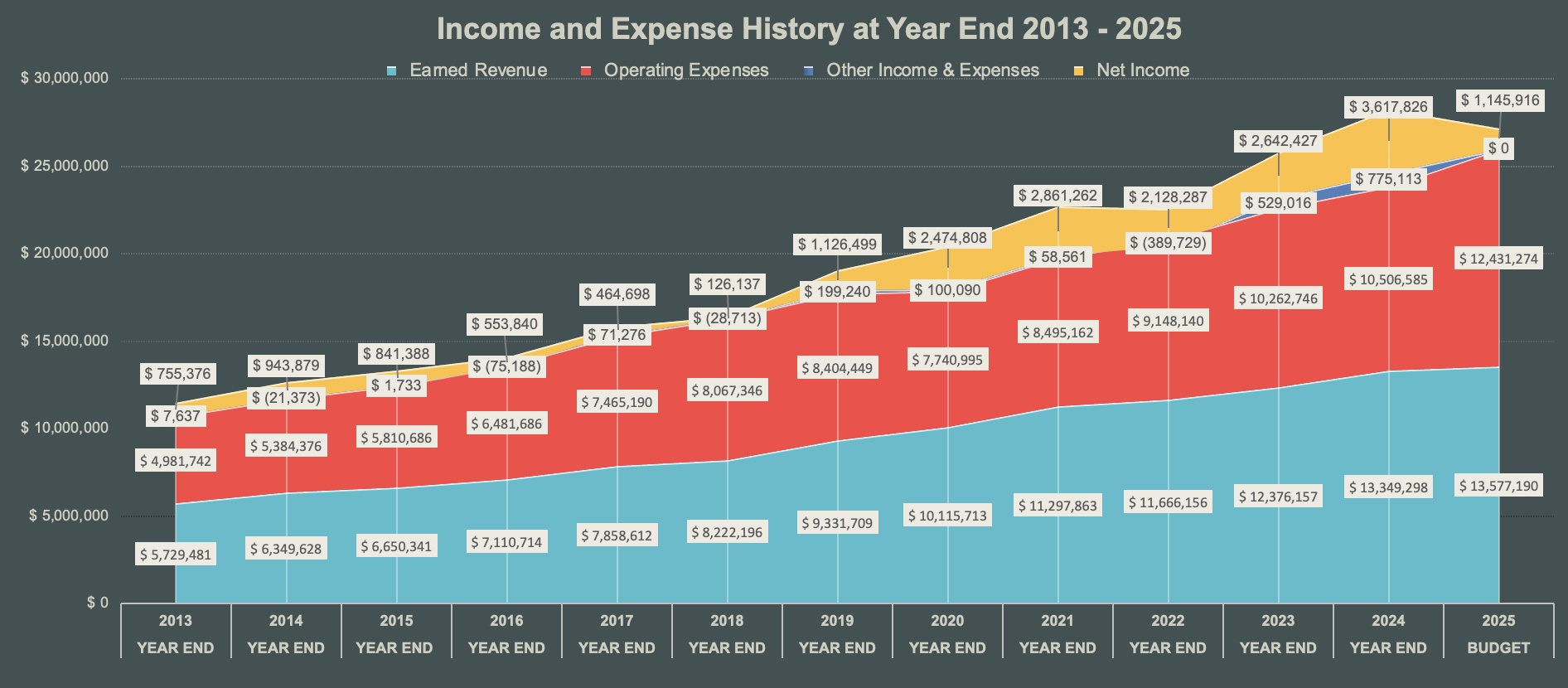
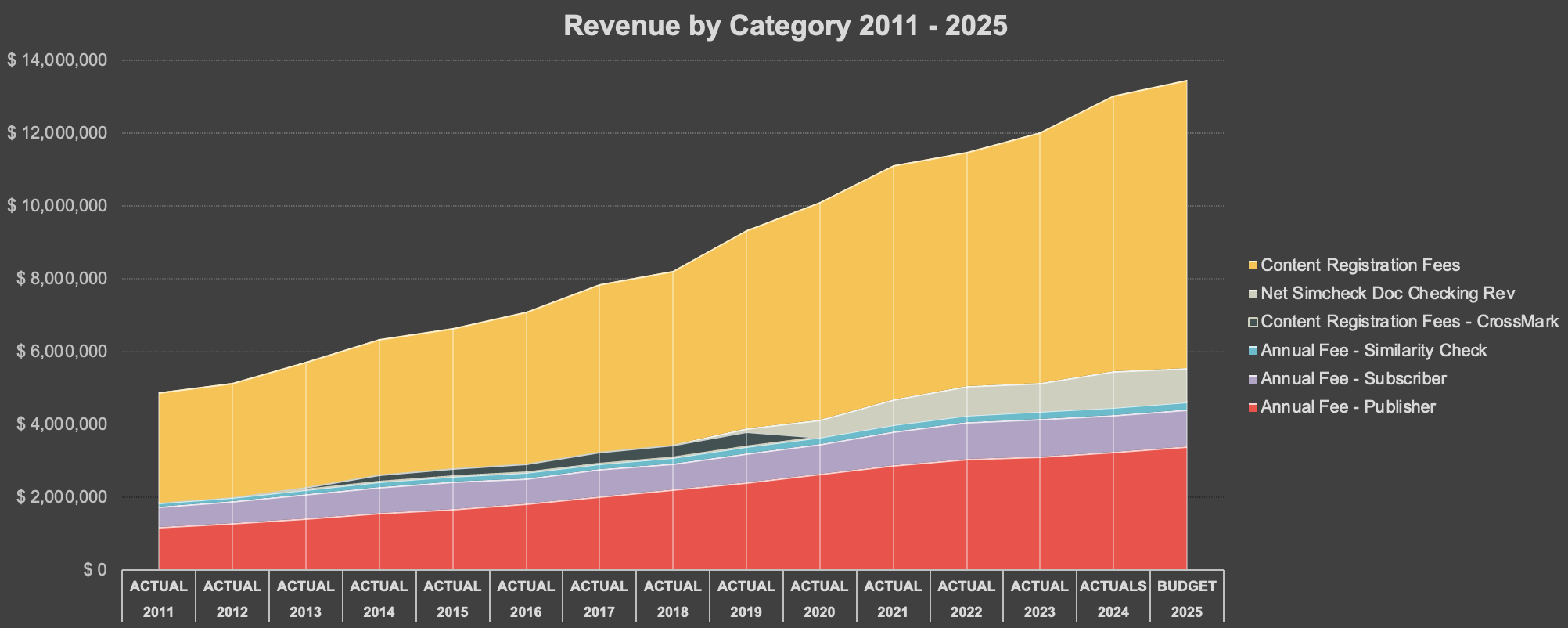
We operate on a budget of around $14 million (USD). About one-third of our revenue comes from annual dues (e.g., membership fees, subscriptions) and two-thirds from services (e.g., Content Registration, Similarly Check document checking). Our fees are set and reviewed by the Membership & Fees committee, which includes our staff, board, and community members. This group also created a set of fee principles which were approved by the board in 2019.
About 70% of our expenses are related to people - staff, benefits, and contracted support. 30% of our costs are everything else - hosting costs, licensing fees, events, and costs to do business like banking fees and insurance.
Each year we strive to generate a small operating net and have been able to do so nearly every year.
We also maintain a reserve fund to support long-term sustainability. We periodically report on our progress towards fulfilling the Principles of Open Scholarly Infrastructure: 2020, 2022, 2024
Below is a look at how our operations have changed over time.
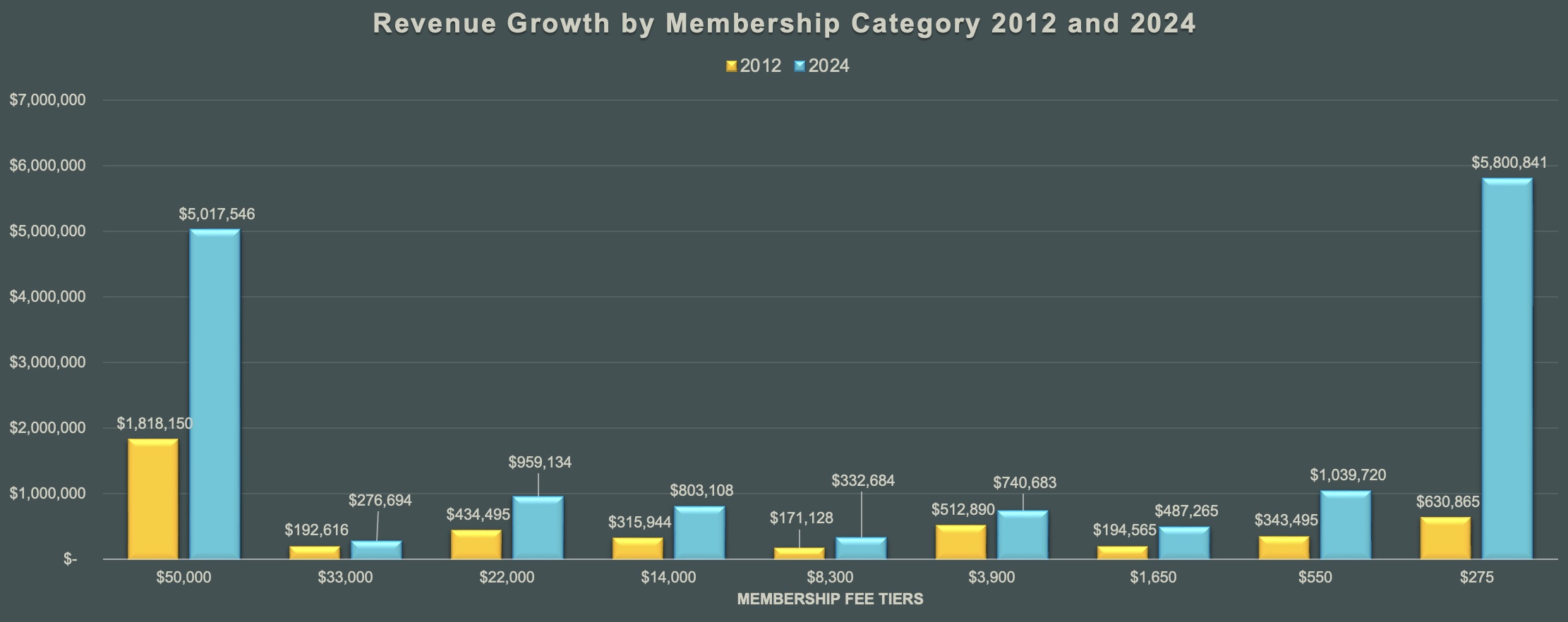
The majority of our revenue comes from members in smallest and largest tiers. We have seen the most growth in revenue from the smallest fee tier.F
Annual financial reporting
As a not-for-profit, we are tax-exempt, and to maintain that status, we undergo a financial audit each year by an independent accounting firm. Our auditors prepare our Form 990, which the US IRS requires and is made publicly available. It gives an overview of what we do, how we are governed, and detailed financial information.
Below are our recent Form 990s and audited financial statements.