PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
To work out which version you’re on, take a look at the website address that you use to access iThenticate. If you go to ithenticate.com then you are using v1. If you use a bespoke URL, https://crossref-[your member ID].turnitin.com/ then you are using iThenticate 2.0.
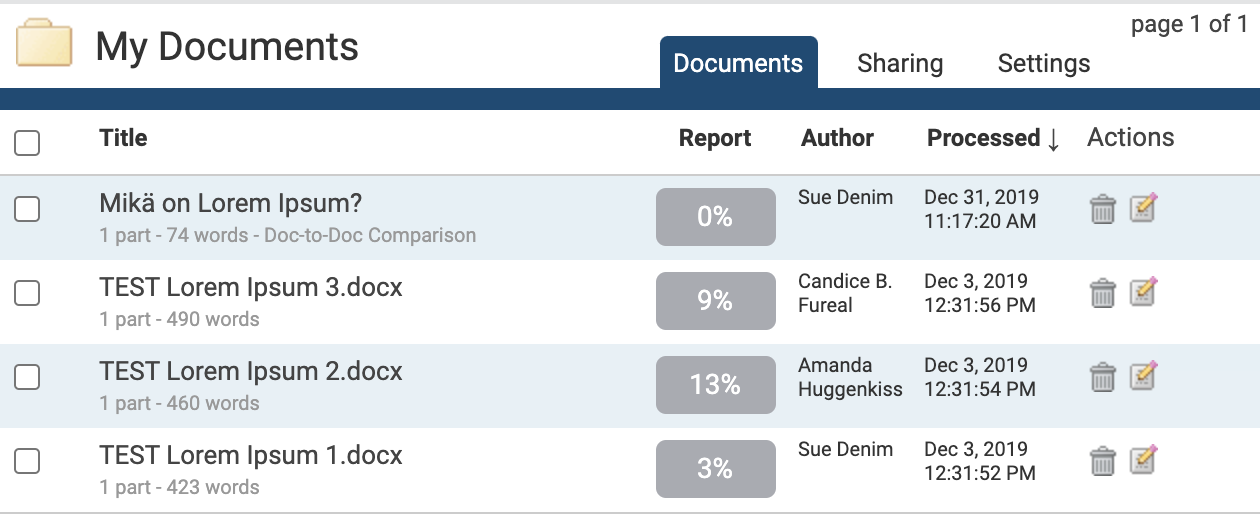
Within a folder, the Documents tab shows all the submitted documents for that folder.
Each document submitted generates a Similarity Report after the document has been through the Similarity Check. If more documents are present than can be displayed at once, the pages feature will appear beneath the documents - click the page number to display, or click Next to move to the next page of documents.
zip file upload - to submit a zip file containing multiple documents, up to a maximum of 100MB or 1,000 files. Larger files may take longer to upload
cut & paste - to submit text directly into the submission box. Use this to copy and paste a submission from a file format that is not supported. This method supports plain text only (no images or non-text information)
iThenticate currently accepts the following file types for document upload:
Microsoft Word® (.doc and .docx)
Word XML
plain text (.txt)
Adobe PostScript®
Portable Document Format (.pdf)
HTML
Corel WordPerfect® (.wpd)
Rich Text Format (.rtf)
Each file may not exceed 400 pages, and each file size may not exceed 100 MB. Reduce the size of larger files by removing non-text content. You can’t upload or submit to iThenticate files that are password-protected, encrypted, hidden, system files, or read-only.
.pdf documents must contain text - if they contain only images of text, they will be rejected during the upload attempt. To check, copy and paste a section of the .pdf into a plain-text editor such as Microsoft Notepad® or Apple TextEdit®. If no text is copied over, the selection does not contain text.
To convert scanned images of a document, or an image saved as a .pdf, use Optical Character Recognition (OCR) software to convert the image to text. The conversion software can introduce errors, so manually check and correct the converted document.
Some document formats can contain multiple data types, such as text, images, embedded information from another file, and formatting. Non-text information that is not saved directly within the document will not be included in a file upload, for example, references to a Microsoft Excel® spreadsheet included within a Microsoft Office Word® document.
Use a word-processing program to save your file as one of the accepted types listed above, such as .rtf or .txt. Neither file type supports images or non-text data within the file. Plain text format does not support any formatting, and rich text format allows only limited formatting.
When converting a file to a new format, save it with a different name from the original, to avoid accidentally overwriting the original file. This is especially important when converting to plain text or rich text formats, to prevent permanent loss of the original formatting or image content of the file.
Page maintainer: Kathleen Luschek Last updated: 2020-May-19