PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Copyright is a type of intellectual property, which allows the copyright owner to protect against others copying or reproducing their work. Copyright arises automatically when a work that qualifies for protection is created. Scholarly communications relies on researchers sharing, adapting, and building on the work of others, so a license (an official permission or permit) is needed in order for copyrighted content to be used in these ways.
Including license information (or access indicators) in your deposit is very helpful in letting readers know how they can access and use your content, for example, in text and data mining. You can include access indicators in metadata deposits.
Note that free-to-read is an access indicator, separate from the license. It’s used to show that a work is available at no charge for a limited time, but would normally be behind a paywall.
Access indicators may be included in a metadata deposit, submitted as a resource-only deposit, or as a supplemental metadata upload, and may be included with Crossmark metadata where applicable. The ai namespace must be included in the schema declaration, for example:
This guidance for members on how to register better license metadata with us is to help academic institutions identify content written by their researchers, and how this content may be used, particularly in an automated, machine-readable way.
Institutions need to know which article version may be exposed on an open repository, and from what date. It is no longer sufficient simply to describe in words how they may calculate the embargo end-date, for example, by referring them to a general set of terms and conditions that apply to all of your content across its whole lifecycle – they need to know whether this version of this article can be exposed on their repository and, if so, from what specific date, and what repository readers can then do with the content they find there.
Our schema contains all the fields you need to specify this unambiguously. By doing so, you can also be more confident that institutions will have the information they need to respect your terms and conditions.
A single Crossref DOI can be associated with metadata relating to multiple versions of a work: the author’s accepted manuscript (AAM), version of record (VoR), or a version intended for text and data mining (TDM). Each of these versions can have their own license conditions attached to them. To reflect this, works registered with us can have multiple license elements. Each license element can contain a URL to a license, the article version to which the license applies, and the license start date. Together, these can describe nuanced license terms across different versions of the work.
An analysis done by Jisc of our metadata found that while 48% of journal articles published in 2017 had license information, the licenses most often referred to the text and data mining version of the work, and licenses were still being used inconsistently for the version of record (VoR) or accepted manuscript (AM).
A major concern is that many members link to their general terms and conditions rather than to licenses that apply at specific times to specific versions of a work. For example, a member may set its policies out in a general terms and conditions page, and link to it in the license metadata:
On the terms and conditions page, the member could spell out, for example, the license that applies to the VoR, the restrictions that apply to the AAM during its embargo period, and details of how the AAM may be used after its embargo period. A repository manager would then have to go through the terms and conditions, and manually calculate the embargo end date, in order to determine whether the work could be deposited to a repository. This is a prohibitively onerous process for institutions, and risks content being used outside the terms of member policies because of human error.
It would be helpful if members could instead set out specific licenses for each stage in each article’s lifecycle, for each of its versions. If the licensing terms for a version will change (for example, because it may be exposed on a repository after an embargo period), then a separate license should be used, with the start_date element indicating when the new license comes into effect. Using start dates for this license information is best practice in general, as it can validate immediate open access, which is at the heart of many institutional and funder policies. This is set out in more detail in the examples below.
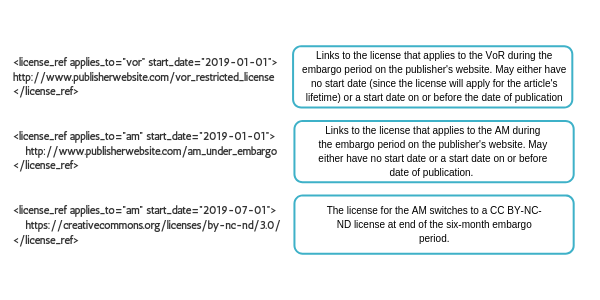
Example: Green OA with Creative Commons license
In this example, a work is published on 1 January 2019. Under the member’s policy, the VoR is under access controls. The AAM is under embargo for a six-month period and then becomes open access under a CC BY NC ND license.
Green OA with Creative Commons license
By using a Creative Commons license with a start date, the embargo end date can be unambiguously deduced from the metadata.
Example: Green OA with member-defined post-embargo license
Linking to a Creative Commons license is optimal whenever possible, as this is an unambiguously open license and so will be readily recognizable as identifying the post-embargo period. It is also a standard license which makes it more easily machine-readable. However, if you need to define your own open license, you can instead link to that in the metadata along with the appropriate start date.
Green OA with member-defined post-embargo license
Repository managers will still be able to unambiguously distinguish works that can be made available after an embargo period, albeit involving a brief manual check, provided the license identifies itself explicitly as referring specifically to the post-embargo period.
It would not be suitable to provide a single URL containing license terms for both the pre-embargo and post-embargo period, for example:
This would not allow institutions to unambiguously determine the embargo end date and license, and so should be avoided.
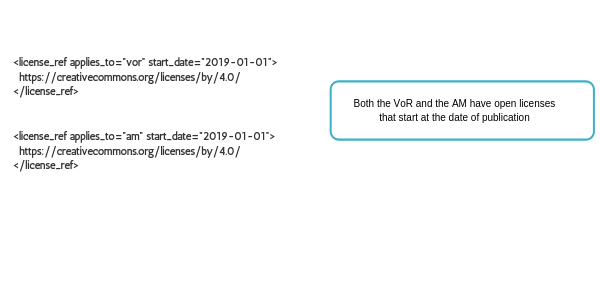
Example: Gold OA
In the case of gold OA, the licenses are simple: both the AAM and the VoR have an open license (in this example, CC BY) that starts no later than the date of publication. The start date could optionally be omitted entirely, since the license terms will apply for the article’s lifetime.
Gold OA license
Use cases
Having clear, unambiguous license metadata helps institutions use the content within your terms and conditions. For example, an institution could query our APIs to find works published by researchers at their organisation (provided you have also populated the affiliations of all the (co-)authors), and check programmatically for the presence and with-effect dates of any open license(s). This would show whether (and if so when) the work can be exposed on their repository.
How to add license information to your Crossref metadata
There are multiple ways that members can add license information to the metadata they deposit/have deposited with us:
How to register license information as part of a resource-only deposit
<body><!-- license updates with dates / free to read info included--><lic_ref_data><doi>10.5555/pubdate1</doi><ai:programname="AccessIndicators"><ai:free_to_read/><ai:license_refapplies_to="vor"start_date="2011-01-11">https://www-crossref-org.turing.library.northwestern.edu/vor-license</ai:license_ref><ai:license_refapplies_to="am"start_date="2012-01-11">https://www-crossref-org.turing.library.northwestern.edu/am-license</ai:license_ref><ai:license_refapplies_to="tdm"start_date="2012-01-11">https://www-crossref-org.turing.library.northwestern.edu/tdm-license</ai:license_ref></ai:program></lic_ref_data><!-- license updates with just license URL included--><lic_ref_data><doi>10.5555/pubdate1</doi><ai:programname="AccessIndicators"><ai:free_to_read/><ai:license_ref>https://www-crossref-org.turing.library.northwestern.edu/vor-license</ai:license_ref></ai:program></lic_ref_data></body>
Page maintainer: Isaac Farley Last updated: 2024-February-16