Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
The ‘Research Nexus’ is the vision to which we aspire:
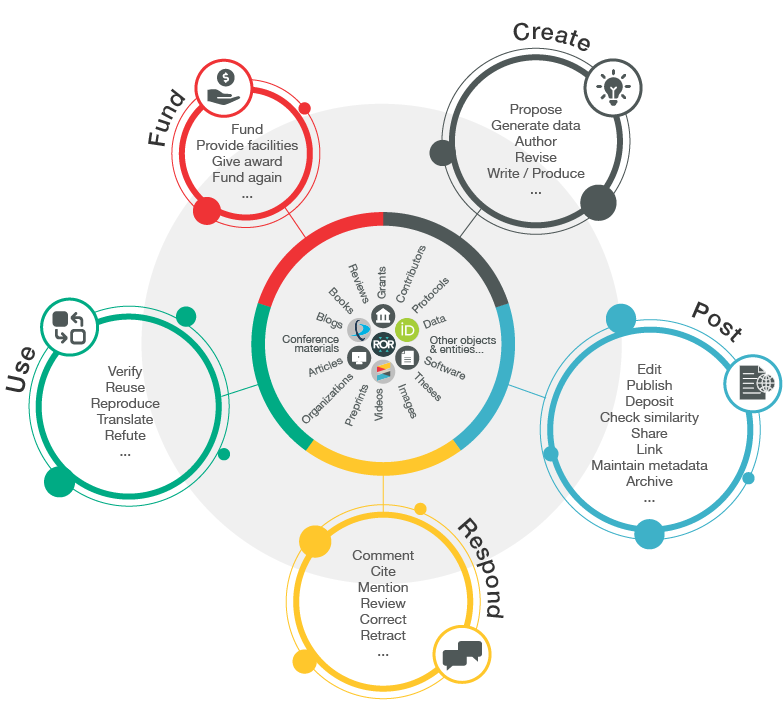
A rich and reusable open network of relationships connecting research organisations, people, things, and actions; a scholarly record that the global community can build on forever, for the benefit of society.
The Research Nexus goes beyond the basic idea of just having persistent identifiers for content. Objects and entities such as journal articles, book chapters, grants, preprints, data, software, statements, dissertations, protocols, affiliations, contributors, etc. should all be identified and that is still an important part of the picture. But what is most important is how they relate to each other and the context in which they make up the whole research ecosystem.
The foundation of the Research Nexus is metadata; the richer and more comprehensive the metadata in Crossref records, the more value there is for our members and for others, including for future generations.
Crossref Research Nexus Vision
Metadata and relationships between research objects and entities can support the whole scholarly research ecosystem in many ways, including:
Research integrity: helping to provide signals about the trustworthiness of the work including provenance information such as who funded it (when and for how much), which organisations and people contributed what, whether something was updated or corrected, and whether it was checked for originality. All of these signals can be expressed through Crossref metadata.
Reproducibility: helping others to reproduce outcomes by adding relationships between literature, data, software, protocols and methods, and more. All of these relationships can be asserted through members’ ongoing stewardship of their Crossref metadata records.
Reporting and assessment: helping organisations such as universities, funders, governments, to track and demonstrate the outcomes of investment; provide benchmarking information; show compliance with funder mandates; and decide what other research to fund. This kind of information can be included in Crossref metadata.
Discoverability: helping people and systems identify work through multiple angles. Registering content with Crossref makes it possible for work to be found and used. Thousands of systems use Crossref metadata, therefore the richer the records are, the more visibility there is likely to be of your work. Including metadata like abstracts and references are very simple ways to increase the visibility of your records.
The importance of relationships
A big part of the Research Nexus is establishing connections between and among different research objects which establishes provenance over time. Adding relationships to your metadata records can convey much richer and more nuanced connections beyond traditional references.
These relationships may consist of versions, corrections, translations, data, formats, supplements, and components. There are no extra fees for including relationships in your metadata.
What types of resources and records can be registered with Crossref?
We are working to make our input schema more flexible so that almost any type of object can be registered and distributed openly through Crossref. At the moment, members tend to register the following:
Conference proceedings: information about a single conference and records for each conference paper/proceeding.
Datasets: includes database records or collections.
Dissertations: includes single dissertations and theses, but not collections.
Grants: includes both direct funding and other types of support such as the use of equipment and facilities.
Journals and articles: at the journal title and article level, and includes supplemental materials as components.
Peer reviews: any number of reviews, reports, or comments attached to any other work that has been registered with Crossref.
Pending publications: a temporary placeholder record with minimal metadata, often used for embargoed work where a DOI needs to be shared before the full content is made available online.
Preprints and posted content: includes preprints, eprints, working papers, reports, and other types of content that has been posted but not formally published.