As our global community continues to grow, it is important for us to build and maintain our connections within it. In March this year, we had the opportunity to visit São Paulo for a community event at the Fundação Getúlio Vargas. The content of our presentations is available online. Events such as this provide an opportunity for us to update our members on Crossref fundamentals and developments, and help us better tune in to the varied needs of our communities and learn how we can work together more effectively. This was our third visit to Brazil, with previous events held in Campinas and São Paulo in 2016, and Goiânia and Fortaleza in 2018.
Each organization in the global community of Crossref members (that’s currently over 24k organizations in 166 different countries) plays a key role in building the Research Nexus. Any opportunity we have to meet with our members in person is a highlight and a way for us to learn more from each other. The month of January saw three of us travel to Bangkok to attend the first-ever Charleston Conference organised in Asia and to meet with our growing community in Thailand.
This year, we placed a spotlight on the Latin American community, hosting the second Crossref Metadata Sprint in São Paulo, Brazil from 4 - 6 March 2026. In our first tri-lingual event, we brought together 31 participants from Argentina, Brazil, Colombia, Ecuador, and Mexico. Our goal was to foster community co-creation using the open scholarly metadata. The Sprint was an opportunity to pose questions, share ideas, collaborate on research, and propose innovative solutions that enhance the use of metadata in scholarly communication and beyond.
Read on for more details about the content of the Sprint, and the resulting projects. You can also register to join our Sprint Showcase call on 22nd April to hear directly from the team about their creations.
On 17 March 2026, we experienced an outage that affected DOI resolution for Crossref DOIs and the deposit of metadata records by Crossref members. In this summary, we outline what happened, the impact on our community, and the steps we are taking to strengthen our systems and processes as a result.
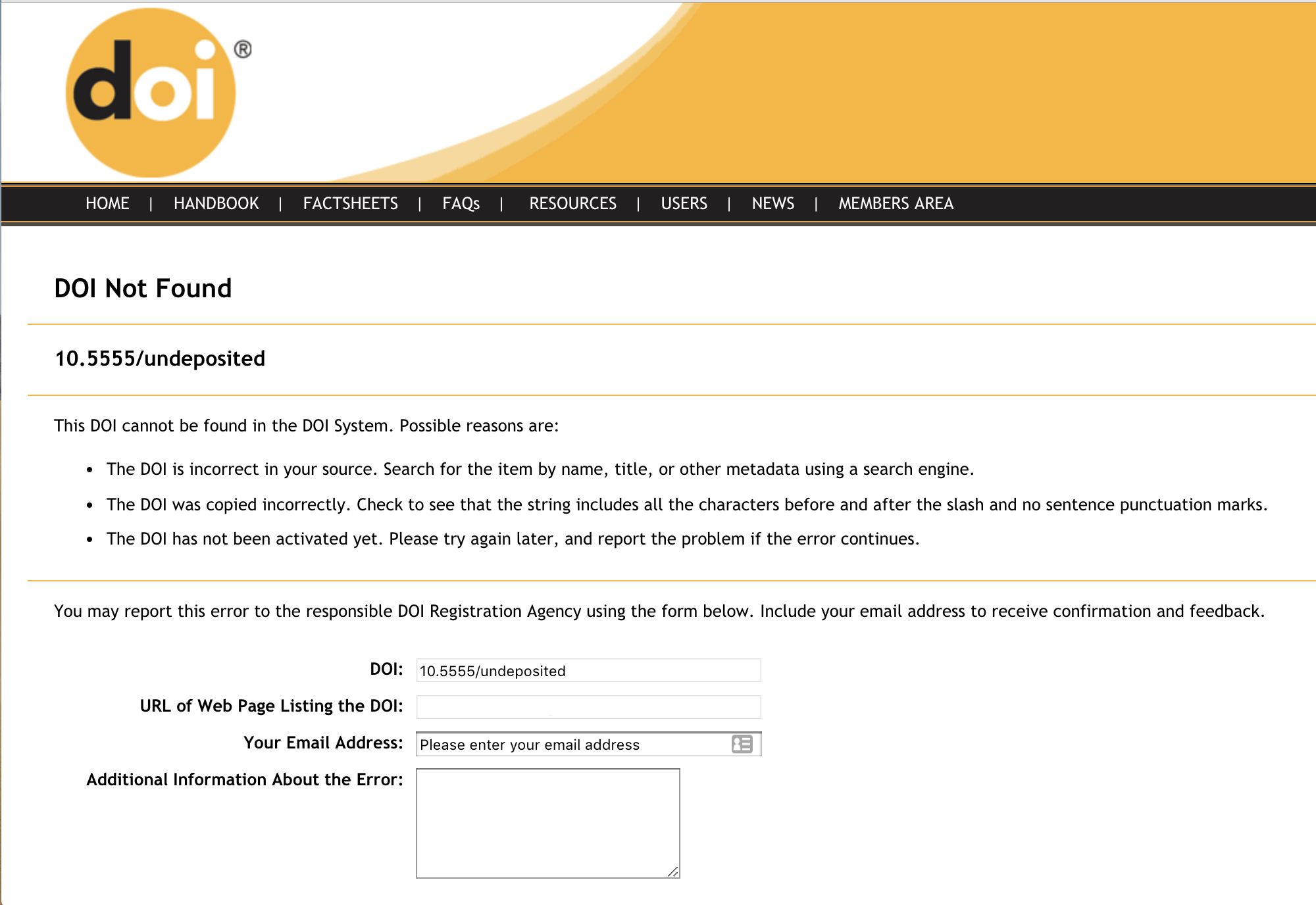
The DOI error report is sent immediately when a user informs us that they’ve seen a DOI somewhere which doesn’t resolve to a website.
The DOI error report is used for making sure your DOI links go where they’re supposed to. When a user clicks on a DOI that has not been registered, they are sent to a form that collects the DOI, the user’s email address, and any comments the user wants to share. We compile the DOI error report daily using those reports and comments, and send it via email to the technical contact at the member responsible for the DOI prefix as a .csv attachment.
If you would like the DOI error report to be sent to a different person, please contact us.
The DOI error report .csv file contains (where provided by the user):
DOI - the DOI being reported
URL - the referring URL
REPORTED-DATE - date the DOI was initially reported
USER-EMAIL - email of the user reporting the error
COMMENTS
We find that approximately 2/3 of reported errors are ‘real’ problems. Common reasons why you might get this report include:
you’ve published/distributed a DOI but haven’t registered it
the DOI you published doesn’t match the registered DOI
a link was formatted incorrectly (a . at the end of a DOI, for example)
a user has made a mistake (confusing 1 for l or 0 for O, or cut-and-paste errors)
What should I do with my DOI error report?
Review the .csv file attached to your emailed report, and make sure that no legitimate DOIs are listed. Any legitimate DOIs found in this report should be registered immediately. When a DOI reported via the form is registered, we’ll send out an alert to the reporting user (if they’ve shared their email address with us).
I keep getting DOI error reports for DOIs that I have not published, what do I do about this?
It’s possible that someone is trying to link to your content with the wrong DOI. If you do a web search for the reported DOI you may find the source of your problem - we often find incorrect linking from user-provided content like Wikipedia, or from DOIs inadvertently distributed by members to PubMed. If it’s still a mystery, please contact us.
Page maintainer: Isaac Farley Last updated: 2024-July-19