Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
Last year I spent several weeks studying how to automatically match unstructured references to DOIs (you can read about these experiments in my previous blog posts). But what about references that are not in the form of an unstructured string, but rather a structured collection of metadata fields? Are we matching them, and how? Let’s find out.
TL;DR
43% of open/limited references deposited with Crossref have no publisher-asserted DOI and no unstructured string. This means they need a matching approach suitable for structured references. [EDIT 6th June 2022 - all references are now open by default].
I adapted our new matching algorithms: Search-Based Matching (SBM) and Search-Based Matching with Validation (SMBV) to work with both structured and unstructured references.
I compared three matching algorithms: Crossref’s current (legacy) algorithm, SBM and SBMV, using a dataset of 2,000 structured references randomly chosen from Crossref’s references.
SBMV and the legacy algorithm performed almost the same. SBMV’s F1 was slightly better (0.9660 vs. 0.9593).
Similarly as in the case of unstructured references, SBMV achieved slightly lower precision and better recall than the legacy algorithm.
Introduction
Those of you who often read scientific papers are probably used to bibliographic references in the form of unstructured strings, as they appear in the bibliography, for example:
[5] Elizabeth Lundberg, “Humanism on Gallifrey,” Science Fiction Studies, vol. 40, no. 2, p. 382, 2013.
This form, however, is not the only way we can store the information about the referenced paper. An alternative is a structured, more machine-readable form, for example using BibTeX format:
@article{Elizabeth_Lundberg_2013,
year = 2013,
publisher = {{SF}-{TH}, Inc.},
volume = {40},
number = {2},
pages = {382},
author = {Elizabeth Lundberg},
title = {Humanism on Gallifrey},
journal = {Science Fiction Studies}
}
Probably the most concise way to provide the information about the referenced document is to use its identifier, for example (🥁drum roll…) the DOI:
It is important to understand that these three representations (DOI, structured reference and unstructured reference) are not equivalent. The amount of information they carry varies:
The DOI, by definition, provides the full information about the referenced document, because it identifies it without a doubt. Even though the metadata and content are not directly present in the DOI string, they can be easily and deterministically accessed. It is by far the preferred representation of the referenced document.
The structured reference contains the metadata of the referenced object, but it doesn’t identify the referenced object without a doubt. In our example, we know that the paper was published in 2013 by Elizabeth Lundberg, but we might not know exactly which paper it is, especially if there are more than one document with the same or similar metadata.
The unstructured reference contains the metadata field values, but without the names of the fields. This also doesn’t identify the referenced document, and even its metadata is not known without a doubt. In our example, we know that the word “Science” appears somewhere in the metadata, but we don’t know for sure whether it is a part of the title, journal title, or maybe the author’s (very cool) name.
The diagram presents the relationships between all these three forms:
The arrows show actions that Crossref has to perform to transform one form to another.
Green transformations are in general easy and can be done without introducing any errors. The reason is that green arrows go from more information to less information. We all know how easy it is to forget important stuff!
Green transformations are typically performed when the publication is being created. At the beginning the author can access the DOI of the referenced document, because they know exactly which document it is. Then, they can extract the bibliographic metadata (the structured form) of the document based on the DOI, for example by following the DOI to the document’s webpage or retrieving the metadata from Crossref’s REST API. Finally, the structured form can be formatted into an unstructured string using, for example, the CiteProc tool.
We’ve also automated it further and these two green transformation (getting the document’s metadata based on the DOI and formatting it into a string) can be done in one go using Crossref’s content negotiation.
Red transformations are often done in systems that store bibliographic metadata (like our own metadata collection), often at a large scale. In these systems, we typically want to have DOIs (or other unique identifiers) of the referenced documents, but in practise we often have only structured and/or unstructured form. To fix this, we match references. Some systems also perform reference parsing (thankfully, we discovered we do not need to do this in our case).
In general, red transformations are difficult, because we have to go from less information to more information, effectively recreating the information that has been lost during paper writing. This requires a bit of reasoning, educated guessing, and juggling probabilities. Data errors, noise, and sparsity make the situation even more dire. As a result, we do not expect any matching or parsing algorithm to be always correct. Instead, we perform evaluations (like in this blog post) to capture how well they perform on average.
My previous blog post focused on matching unstructured references to DOIs (long red “matching” arrow). In this one, I analyse how well we can match structured references to DOIs (short red “matching” arrow).
References in Crossref
You might be asking yourself how important it is to have the matching algorithm working for both structured and unstructured references. Let’s look more closely at the references our matching algorithm has to deal with.
29% of open/limited references deposited with Crossref already have the DOI provided by the publisher member. At Crossref, when we come across those references, we start dancing on a rainbow to the tunes of Linkin Park, while the references holding their DOIs sprinkle from the sky. Some of us sing along. We live for those moments, so if you care about us, please provide as many DOIs in your references as possible!
You might be wondering how we are sure these publisher-provided DOIs are correct. The short answer is that we are not. After all, the publisher might have used an automated matcher to insert the DOIs before depositing the metadata. Nevertheless, our current workflow assumes these publisher-provided DOIs are correct and we simply accept them as they are.
Unfortunately, the remaining 71% of references are deposited without a DOI. Those are the references we try to match ourselves.
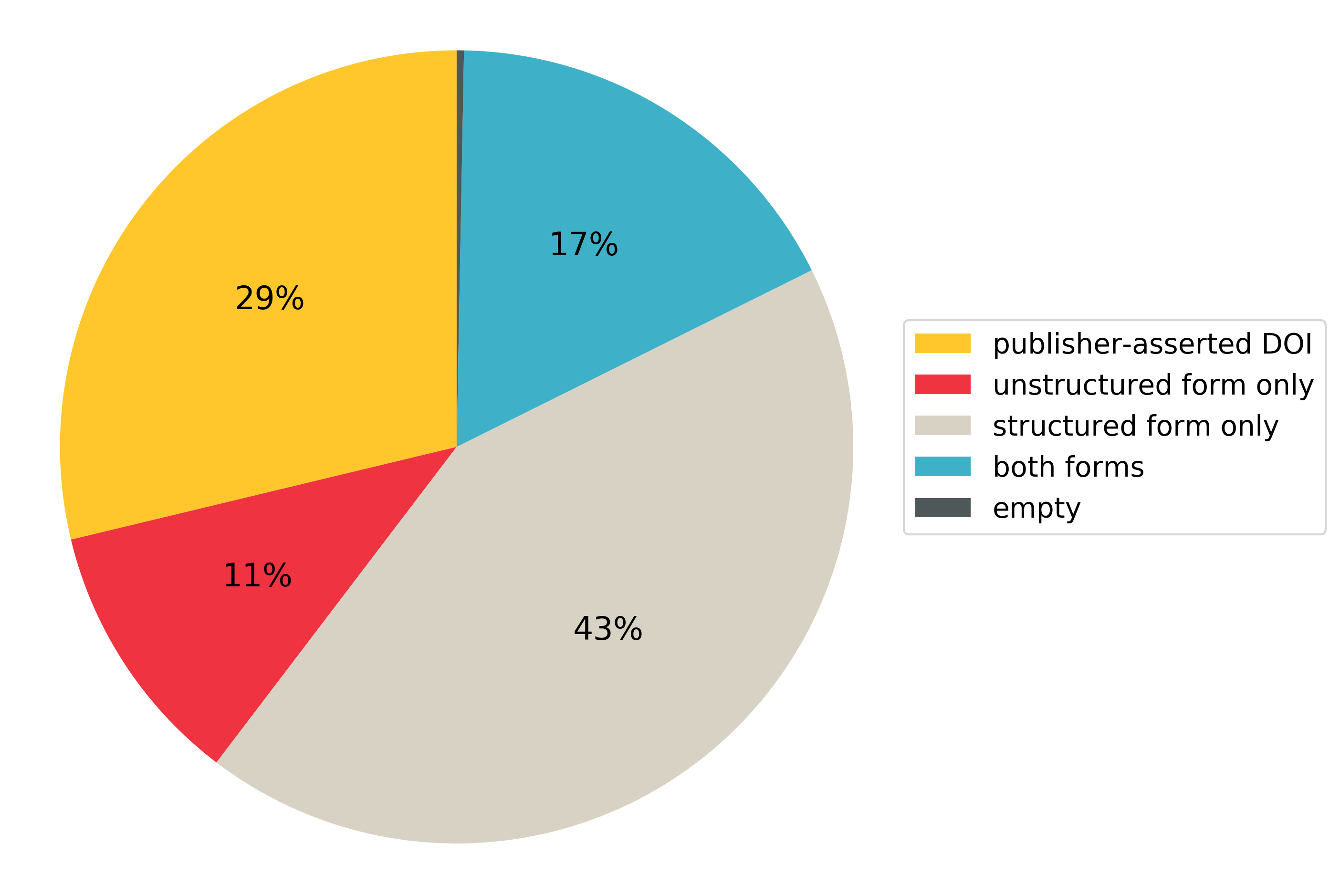
Here is the distribution of all the open/limited references:
17% of the references are deposited with no DOI and both structured and unstructured form. 11% have no DOI and only an unstructured form, and 43% have no DOI and only a structured form. These 43% cannot be directly processed by the unstructured matching algorithm.
This distribution clearly shows that we need a matching algorithm able to process both structured and unstructured references. If our algorithm worked only with one type, we would miss a large percentage of the input references, and the quality of our citation metadata would be questionable.
The analysis
Let’s get to the point. I evaluated and compared three matching algorithms, focusing on the structured references.
The first algorithm is one of the legacy algorithms currently used in Crossref. It uses fuzzy querying in a relational database to find the best matching DOI for the given structured reference. It can be accessed through a Crossref OpenURL query.
The second algorithm is an adaptation of the Search-Based Matching (SBM) algorithm for structured references. In this algorithm, we concatenate all metadata fields of the reference and use it to search in the Crossref’s REST API. The first hit is returned as the target DOI if its relevance score exceeds the predefined threshold.
The third algorithm is an adaptation of the Search-Based Matching with Validation (SBMV) for structured references. Similarly as in the case of SBM, we also concatenate all metadata fields of the input reference and use it to search in the Crossref’s REST API. Next, a number of top hits are considered as candidates and their similarity score with the input reference is calculated. The candidate with the highest similarity score is returned as the target DOI if its score exceeds the predefined threshold. The similarity score is based on fuzzy comparison of the metadata field values between the candidate and the input reference.
I compared these three algorithms on a test set composed of 2,000 structured bibliographic references randomly chosen from Crossref’s metadata. For each reference, I manually checked the output of all matching algorithms, and in some cases performed additional manual searching. This resulted in the true target DOI (or null) assigned to each reference.
The metrics are the same as in the previous evaluations: precision, recall and F1 calculated over the set of input references.
The thresholds for SBM and SBMV algorithms were chosen on a separate validation dataset. The validation dataset also contains 2,000 structured references with manually-verified target DOIs.
The results
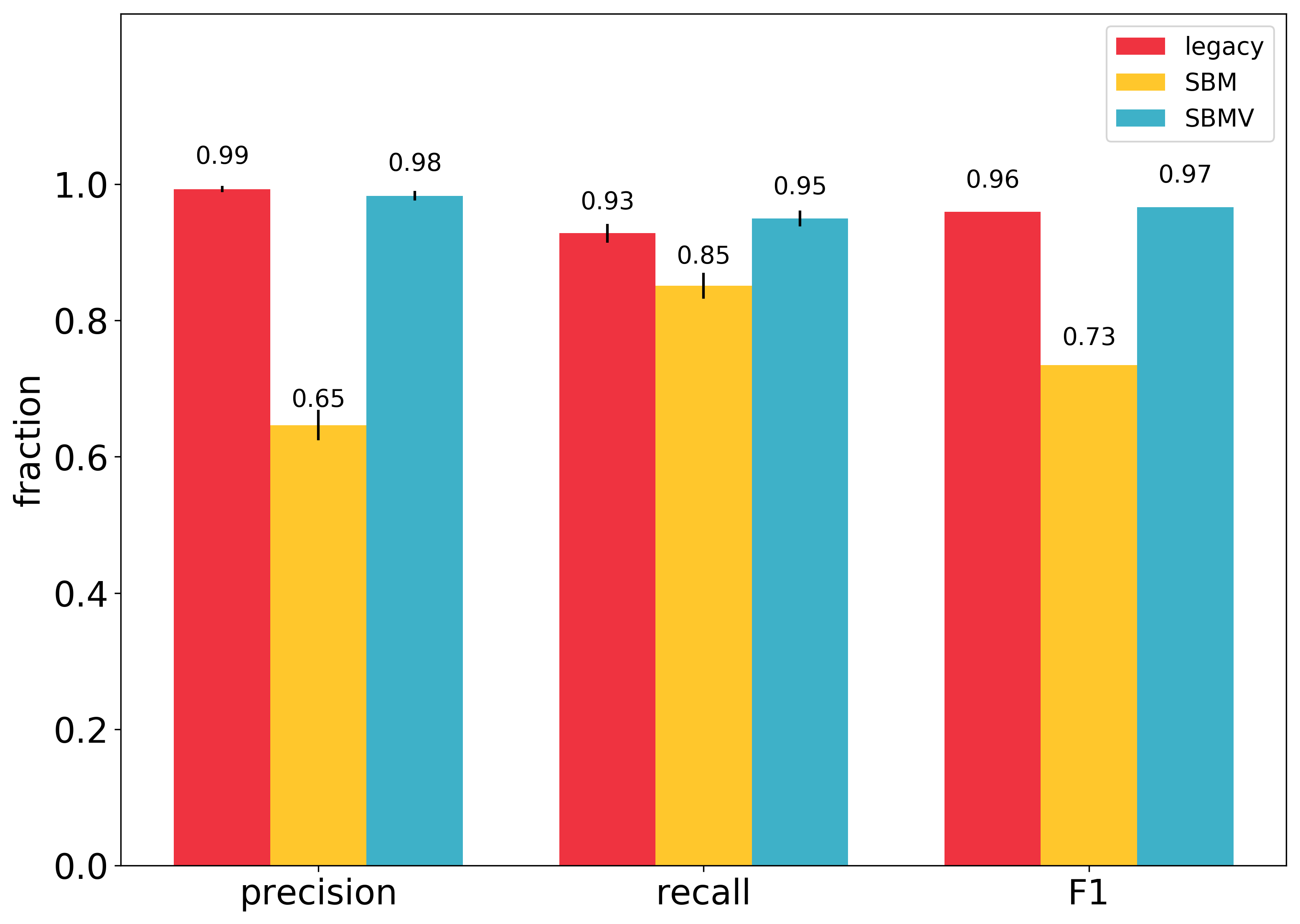
The plot shows the results of the evaluation of all three algorithms:
The vertical black lines on top of the bars represent the confidence intervals.
As we can see, SBMV and the legacy approach achieved very similar results. SBMV slightly outperforms the legacy approach in F1: 0.9660 vs. 0.9593.
SBMV is slightly worse that the legacy approach in precision (0.9831 vs. 0.9929) and better in recall (0.9495 vs. 0.9280).
The SBM algorithm performs the worst, especially in precision. Why is there such a huge difference between SBM and SBMV? The algorithms differ in the post-processing validation stage. SBM relies on the ability of the search engine to select the best target DOI, while SBMV re-scores a number of candidates obtained from the search engine using custom similarity. The results here suggest that in the case of structured references, the right target DOI is usually somewhere close to the top of the search results, but often it is not in the first position. One of the reasons might be missing titles in 76% of the structured references, which can confuse the search engine.
Let’s look more closely at a few interesting cases in our test set:
first-page = 1000
article-title = Sequence capture using PCR-generated probes: a cost-effective method of targeted high-throughput sequencing for nonmodel organisms
volume = 14
author = Peñalba
year = 2014
journal-title = Molecular Ecology Resources
author = Marshall Day C.
volume = 39
first-page = 572
year = 1949
journal-title = India. J. A. D. A.
Above we have most likely a parsing error. A part of the article title appears in the journal name, and the main journal name is abbreviated. ‘I see what you did there, my old friend Parsing Algorithm! Only a minor obstacle!’ said SBMV, and matched the reference to https://doi-org.turing.library.northwestern.edu/10.14219/jada.archive.1949.0114.
volume = 5
year = 2015
article-title = A retrospective analysis of the effect of discussion in teleconference and face-to-face scientific peer-review panels
journal-title = BMJ Open
In this case we have a mismatch in the page number (“533” vs. “S33”). But did SBMV give up and burst into tears? I think we already know the answer! Of course, it conquered the nasty typo with the sword made of fuzzy comparisons (yes, it’s a thing!) and brought us back the correct DOI https://doi-org.turing.library.northwestern.edu/10.1111/j.1528-1157.1989.tb05823.x.
Structured vs. unstructured
How does matching structured references compare to matching unstructured references?
The general trends are the same. For both structured and unstructured references, SBMV outperforms the legacy approach in F1, achieving worse precision and better recall. This tells us that our legacy algorithms are more strict and as a result they miss some links.
Structured reference matching seems easier than unstructured reference matching. The reason is that when we have the structure, we can compare the input reference to the candidate field by field, which is more precise than using the unstructured string.
Structured matching, however, in practise brings new challenges. One big problem is data sparsity. 15% of structured references without DOIs have fewer than four metadata fields. This is not always enough to identify the DOI. Also, 76% of the structured references without DOIs do not contain the article title, which poses a problem for candidate selection using the search engine.
What’s next?
So far, I have focused on evaluating SBMV for unstructured and structured references separately. 17% of the open/limited references at Crossref, however, have both unstructured and structured form. In those cases, it might be beneficial to use the information from both forms. I plan to perform some experiments on this soon.