Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
This announcement has been in the works for some time, but everything seems to take longer when there is a pandemic going on, including finding time and headspace to plan out our strategy for the next few years.
Over the last year or so we have had our heads down addressing how to scale our 20-yr-old system and operation – and adapting to new ways of working. But we’ve also spent time talking to people, forging alliances, looking ahead, and making plans. So we’re happy to now let everyone know exactly what we’ve been up to lately, what we are heading towards in 2025, and what projects and programs are prioritised on our near-term agenda.
Come to next week’s mid-year update webinar to hear what’s happening and up next.
The emergence of a strategic agenda
2018 seems like a decade ago, doesn’t it? Back then we set out a 2018-2021 strategic direction—now archived—that described four goals: adapt to expanding constituencies; simplify and enrich services; selectively collaborate and partner with others; and improve our metadata quality and comprehensiveness. These themes were formed from the output of a planning exercise with our board in mid-2017 which tackled scenarios that remain true today, including: the increasing diversity in scholarly publishing (library-publishing, academic-led journals, shifting geographic dominance, etc.); the growth in preprints and other content formats; the sustainability of scholarly publishing (who is funding it and whether that is an expanding or shrinking pool); and the increase in policy and regulation in this space.
That meeting was the catalyst for embracing openness and a broader set of constituents. It was also decisive about Crossref’s role in this evolving community to focus on our core competencies, defined as:
A reputation as a trusted, neutral one-stop source of metadata and services
Managing scholarly infrastructure with technical knowledge and innovation
Convening and facilitating scholarly community collaboration.
So you can see how we got to focusing on metadata, services, infrastructure, and broad community collaboration.
Ahh, 2019, such an innocent time
When we wrote our post at the end of 2019 A turning point is a time for reflection we highlighted—with data—how different the Crossref community is nowadays. The post also linked to the results of our ‘value’ research project and a fact file which had even more hard data and posed the question Which Crossref initiatives should be top or bottom priorities?. To answer that, the LIVE19 annual meeting group voted (using betting chips) on priority initiatives, with the following results:
Support and implement ROR
Metadata best practices and principles
Support for multiple languages
Address technical and operational debt
Schema updates such as JATS and CRediT
Engagement with funders
We all know what happened next: the collective health and social trauma of the COVID-19 pandemic. All of us struggled. You all did too. Homeschooling, homeworking, homestaying. Caring for—and even saying goodbye to—sick friends and family. Also beloved colleagues. Alongside these unfamiliar new stresses, members were joining in growing numbers, funders kept joining to register grants, conferences went online and we loved them (before then hating them), the number of records we hosted kept going up, and publishing (especially preprints) skyrocketed.
The plan hasn’t actually changed much. Those charts in the 2019 fact file still make for remarkable reading as those same trends continue. We simply haven’t had time to update people on where we are with plans. So it’s high time we give an update on these priorities as well as contextualise them in longer-term goals.
But first, some framing
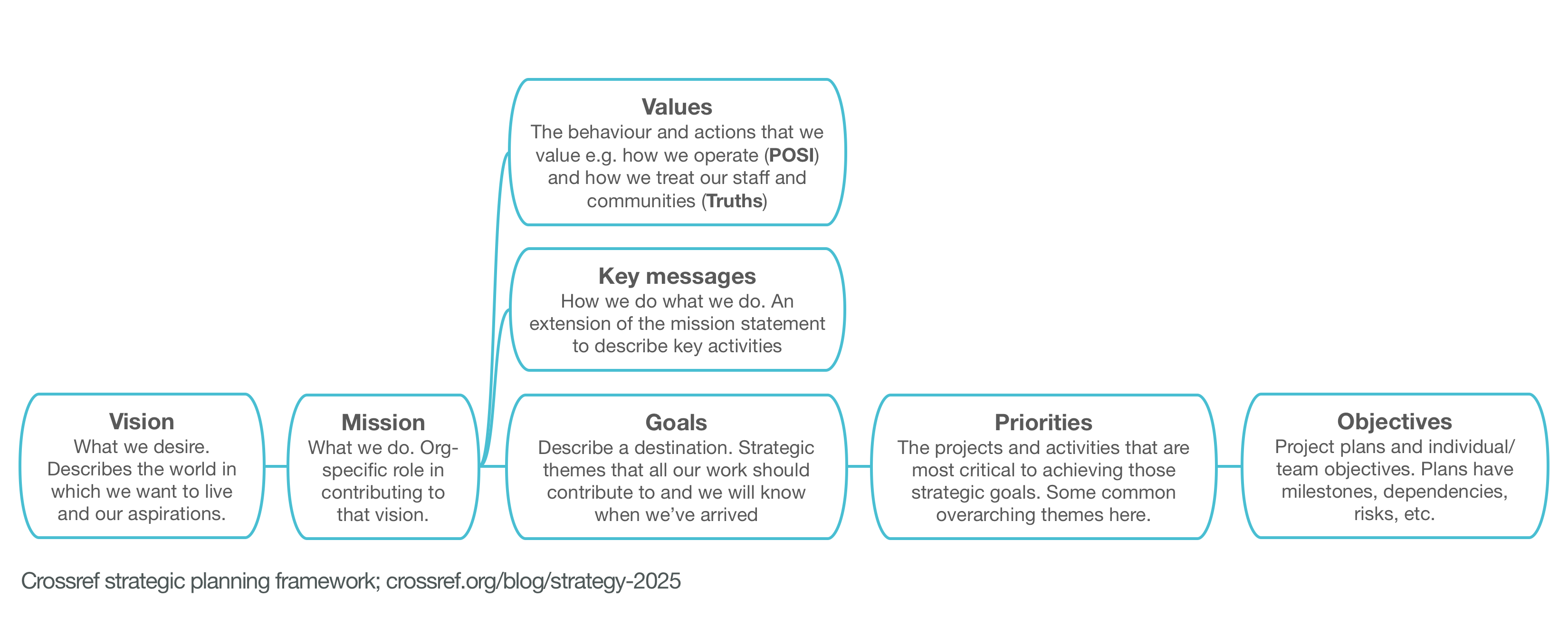
The chart below shows the approach we took to organise our thinking. A lot of it isn’t new; we have had the current mission statement, key messages (rally, tag, run, play, make), and truths since the rebranding work in 2015/2016. More recently, we have added POSI to our values, describing the principles and rules by which we operate as a committed open scholarly infrastructure organisation.
We already have a lot of 'words'. So why do we also need a vision statement and where do the goals fit in? In order to prioritize the things we will work on first, we need to be able to track everything to a higher vision, ensuring that everything we do is working toward an agreed destination. When we have organisation-wide goals, it means that everyone is clear on the direction, is able to prioritize individual and team work, and can see how their contribution fits in. This, in turn, instills confidence, and motivation - amongst staff as well as members and users.
Our working vision statement (feedback needed!) is:
We envision a rich and reusable open network of relationships connecting research organisations, people, things, and actions; a scholarly record that the global community can build on forever, for the benefit of society.
A vision is, of course, shared. It isn’t Crossref-specific but describes the world in which we all want to work together in future.
Now for those contextual six goals
Full details are on the new strategy page but here’s a summary below.
This goal is all about people, support, culture, and resilience. Not just because we’re coming through a panedmic, but also because we’re growing and we need to be able to scale and manage growth more purposefully, with appropriate policies, fees, and resources.
We published a POSI self-assessment earlier this year and like-minded initiatives are following suit. This is a stated goal because we want to be held publicly accountable to the Principles of Scholarly Infrastructure standards of governance, insurance, and sustainability.
This goal centres on growth, strengthening relationships, community facilitation, and content. Working with a growing number of Sponsors helps us lower barriers to participation around the world, including in languages other than English. Expanding the support we offer for research funders and institutions are priorities.
This goal involves researching and communicating the value of richer, connected, and reusable, open metadata, and incentivising people to meet best practices, while also making it possible (and easier) to do so.
We’ve always collaborated but we want to work even more closely with like-minded organisations to solve problems together. Perhaps in future we could also partner with others to find operating efficiencies for our overlapping stakeholders.
This goal is all about focus. And about delivering easy-to-use tools that are critically important for our community. A lot of invisible work has been happening behind the scenes; we’ve been strengthening (and will continue to strengthen) our code-base (while opening up all code) in order to unblock some of the initiatives we know people have been waiting for.
Read more about what projects are included in the above goals in our full 2025 strategic agenda.
You’re invited to a mid-year update webinar
Rather than saving everything for our annual—usually November—meeting, we’ll also do a mid-year update and plan to do so in May or June every year from now on, in addition to the November updates which include the board election and governance and budget information.
This year, we’re covering some of the main product development work we have completed, underway, and planned for the next quarter. We’ll run it live twice - once for those nearby The Americas timezones (June 8th 3pm UTC) and once for those nearby Asia Pacific timezones (June 9th 6am UTC). We have a lot to cover in 90 minutes—including unveiling [our public roadmap[(http://bit.ly/crossref-roadmap)]—but we’re going to try really hard to have a few minutes to discuss questions too.
In the meantime, or indeed anytime, join the discussion over on our community forum - see the discussion below and join in on our forum.
We want to be held accountable to these goals so we’re reliant on you, as a community, to let us know what you think of our 2025 strategic agenda. As always; we’re grateful for your support and advice.