Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, and this is changing now.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
Ten years on from the launch of the Open Funder Registry (OFR, formerly FundRef), there is renewed interest in the potential of openly available funding metadata through Crossref. And with that: calls to improve the quality and completeness of that data. Currently, about 25% of Crossref records contain some kind of funding information. Over the years, this figure has grown steadily. A number of recent publications have shown, however, that there is considerable variation in the extent to which publishers deposit these data to Crossref. Technical but also business issues seem to lie at the root of this. Crossref - in close collaboration with the Dutch Research Council NWO and Sesame Open Science - brought together a group of 26 organisations from across the ecosystem to discuss the barriers and possible solutions. This blog presents some anonymized lessons learned.
There is no Open Science without open metadata
The interest in the potential of this open-source funding metadata seems to be entering a new stage. When registering (or updating) a DOI record for a publication, publishers can include information about the funding of the research. The Open Funder Registry grew out of recommendations in the report from the US Scholarly Publishing Roundtable in 2010. During the Annual Meeting of Crossref that year, Frederick Dylla, CEO of the American Institute of Physics, argued that in order to make research funding information in publications accessible, it needed to be presented in a standard way and stored in a central location.
The benefits of having open funding metadata available, listed by Dylla in his presentation 13 years ago, are still very valid:
Researchers benefit because it increases transparency of their funding sources and supports the requirements they already have from their funders.
For funders, having this data available is essential because it allows them to identify the published outcomes of publicly funded research. Essential to monitor compliance with open access policies, but also important given the pressures funders face to account for their spending of public money.
For publishers, funding metadata provides a valuable service, as it provides insight into how the research they publish is funded.
Although Crossref has been collating funding metadata for many years, there seems to be a renewed interest in this service. Publishers have long expressed a desire to solve the challenges, meta-researchers need this information in order to analyze research on research, editors are concerned with research integrity, including funding trends, and funders themselves need to track the reach and return of their support.
Open Science seems to be an important driver: As we move to an ecosystem built on Open Science principles, not only publications, data, and software need to be openly available, but also the metadata associated with those scholarly outputs. Indeed, in an Open Science world, all meta information should be open, and academia should not be dependent anymore on data from proprietary bibliographic databases. Indicators for research assessment and policy development should be open indicators, derived from open metadata. Much has been done in this area already, in the context of Open Citations and Open Abstracts. While many in the community have focused on the bigger picture of advocating for all open metadata, e.g. Metadata 20/20, open funding metadata is arguably the next big thing. Open Research Information, including open metadata, must be a strategic priority for science and society.
Room for improvement
After ten years of collecting funding metadata, 25% of records in Crossref contain some kind of funding information, and this figure was reached by a steady growth over that time. A number of recent studies have shown, however, that there is room for improvement. A case study published by two of the present authors has shown that the extent to which publishers deposit funding information to Crossref varies considerably. Some larger society presses - American Chemical Society (ACS), American Physical Society (APS), and Royal Society of Chemistry (RSC) - perform exceptionally well, with almost 100% of publications containing funding information. But there is still a large number of publishers - among them large legacy publishers - that attain substantially lower figures or do not seem to deposit funding metadata at all. Our case study has shown that often this cannot be explained by the fact that authors have not provided any funding information, as often this information is available in the acknowledgement sections of the papers. Somehow, however, this data does not find its way to Crossref.
Workflows and challenges: collect, retain, validate, deposit
In order to chart the challenges that publishers face when collecting this information, we organized a roundtable session. 26 organisations were invited from across the ecosystem. These included: major publishers (American Chemical Society, British Medical Journal, Elsevier, IOP Publishing, PLOS, Royal Society of Chemistry, Sage, Springer Nature, Taylor & Francis, and Wiley), funders (European Research Council, Austrian Research Council, Dutch Research Council, OSTI-DOE, UKRI, and Michael J Fox Foundation) as well as service providers (Aries Editorial Manager, PKP / OJS, Scholastica, and eJournal Press).
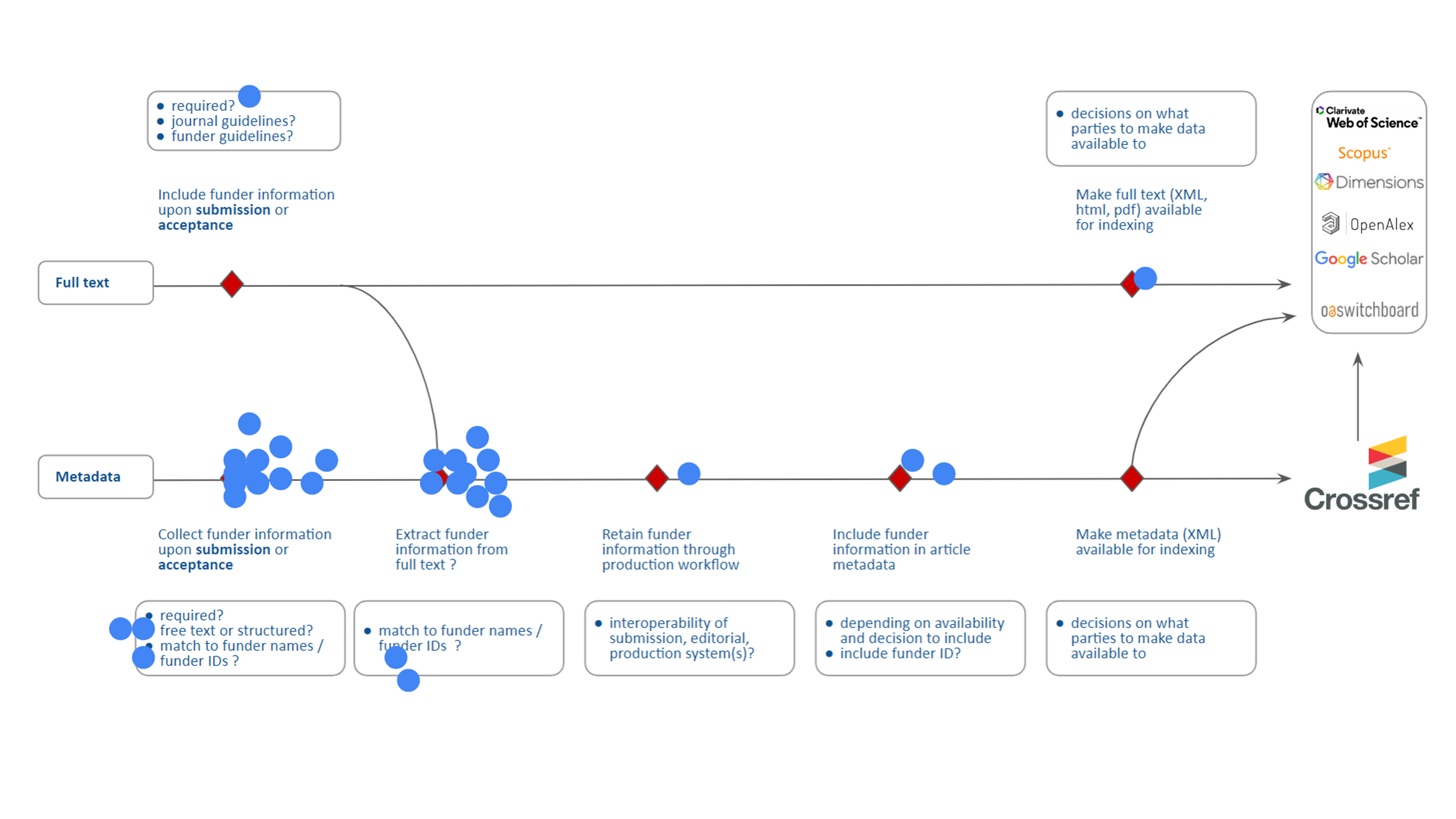
In order to map the potential barriers and challenges publishers face, participants were presented with a workflow scheme representing a hypothetical production process.
This workflow outlined the steps in the production process at which funder information would potentially be handled, as well as some of the considerations that might be at play at each step.
collecting funder information (upon submission or acceptance)
extracting funder information from full text
retaining funder information through the production workflow
including funder information in article metadata
making metadata and/or full text available for indexing
Participants were invited to comment on this workflow and place digital dots in the scheme to identify challenges in the collection, retention, and deposit of funding information. These pain points were afterwards fleshed out in break-out groups.
Lessons learned
1. Still a lack of awareness among editors and authors
For many journals and publishers, collecting funding information starts when papers are submitted through submission systems. Many publishers use the same systems: ScholarOne and Editorial Manager, though many have multiple systems in place for different portfolios of journals. Around 25,000 journals use PKP’s Open Journal System, and Scholastica and eJournal Press are growing in popularity and importance. All of them provide the possibility for authors to enter funder information but this does not by all means mean that all journals make use of it. Submission systems are highly customizable, and publishers tend to tailor systems to the needs and wishes of their journals. Editors who do not see much value in collecting funding metadata therefore present a first ‘weak link’. Publishers and tech providers agreed that more outreach is needed about the importance of funding metadata among editors and authors.
2. Improvements are needed in submission systems
Where journals and publishers agree on asking authors to register funding information through the submission systems, many express a tension between collecting structured metadata and making it as easy as possible for authors. Many are hesitant to use mandatory input fields. Instead, funding metadata is often collected as free text, giving rise to a plethora of ambiguities. Most systems provide suggestions based on the input of the author based on the Open Funder Registry. A lot seems to go wrong at this stage. Authors often persist in the wrong spelling of their funder and do not choose predefined suggestions, making it very difficult to match input to Funder IDs. Publishers estimated the number of non-matches up to 50%. Trivial issues like “Bill & Melinda” versus “Bill and Melinda” or “Netherlands organisation” versus “Netherlands Organisation” result in errors. Here, autocomplete techniques seem to be in dire need of improvement. Based on a preliminary analysis of funder name variants used in Crossref, adding up to 3 of the most frequently used name variants to the list of ‘alternative funder names’ in the Funder registry could solve around 60% of missed matches.
3. A lot can be learned from how some publishers have changed and organized their workflows
Faced with these issues, the Royal Society of Chemistry has invested in innovative workflows to enhance the availability of funding metadata. Instead of relying solely on the free text input of the authors, RSC presented to the group the details of how they have tackled the issue. In addition to author-provided acknowledgements, they work with third-party production vendors to programmatically extract information from the acknowledgement section of papers. Data from the two sources are compared, and when differences or conflicts are being noted, the data is fixed, completed, and reformatted. The next step is crucial - the newly-cleansed funding data is fed back to the author for validation, and retained during the production phase of the paper. Implementation of this validation stage has increased the availability of funding metadata by 30%. In 2023 80% of papers published by RSC have some kind of structured funding metadata. An additional benefit of this feedback loop was its educational effect by alerting authors to the importance of correct funding information. But even RSC continues to struggle with issues of funder name ambiguity, use of acronyms, authors reporting grant or award names instead of funder names, issues with phraseology of funding acknowledgements, and frustrations with the user experience of the service provider integrations with the OFR.
Many publishers agreed that collecting funding information from full-text papers is the preferred option. Not only because it lowers the burden for authors, but also because this potentially renders better data as this is where authors are expected to include this information as part of their funder’s commitments.
4. Retaining information and submitting: no big deal
At the beginning of the workshop, it was expected that maybe the retention of funding information and the propagation through various interlinked systems might pose problems for publishers. However, this was not identified as a problem by participants. Nor was there mention of any challenges in depositing information to Crossref, nor of downstream databases having difficulties retrieving the metadata.
5. There is a genuine interest across the ecosystem to improve funding information in Crossref
While many concluded that there was still a long way to go to solve the many technical challenges related to funding metadata, attendees were unanimous on its importance. Participants agreed that these improvements would require investments from publishers. A willingness to do those was expressed, but also a sense that publishers who do should be incentivised for it, maybe as part of the agreements they have with library consortia. JISC’s recent contract with Taylor & Francis (page 164, Section 7a (iii)) is a good example of how consortia can successfully negotiate the supply of high quality metadata, including funding metadata. It was agreed that another solution could be to allow the additional deposit of the free-text acknowledgement section as a metadata field in Crossref. Instead of educating authors to enter their data correctly or relying on publishers and tech providers to improve their systems to turn free text funder acknowledgement text to structured data, text mining and machine learning could facilitate the improvement of this data.
Next steps
For this workshop, we concentrated on the collection and registration of funding metadata by publishers and did not go into the important, related, issue of the Crossref Grant Linking System (Grant IDs) nor of the plans to further align funder IDs with ROR IDs, both projects that help the community to better record funding information.
Next steps resulting from this community workshop, as
Funders are encouraged to join and register their grants with Crossref DOIs so that registered grants can in future be linked directly to publications and other outputs. About 50 funders have already created around 90,000 grant records. The more grant DOIs that are created by funders, the more likely publishers will be able to prioritize collecting them in their own publication metadata.
Publishers are encouraged to work with their service providers to prioritize the quality of the open funding metadata through Crossref, which is a source for downstream analyses and inclusion by many thousands of tools and services.
Other stakeholders are also offering opportunities to focus on funding metadata, showing a growing interest in the completeness of funder metadata. For example, OA Switchboard’s funder pilot, which also looks at the potential to feed enriched metadata back to Crossref to make them publicly available, and the Open Research Funder Group’s work to promote the improvement of tracking research output, including funding metadata, which includes an active working group in this area.
Crossref will continue to work with publishers and service providers to encourage and make it easier to include funder information in article metadata, including the use of grant identifiers and funder identifiers. Work is underway to bring the Open Funder Registry closer to ROR (Research Organisation Registry), and is planning, at some point in the future, to merge the OFR into ROR, as ROR has a much wider scope and is more broadly community-governed. Crossref has also begun some work on collecting ROR IDs where we currently collect Funder IDs. More technical information is available in this ticket).
We would like to thank all the participants of the workshop for their openness and commitment to working through these issues together. It was a rare opportunity to share insights from publishers, service providers, funders, and researchers - and a useful first step in co-creating a shared understanding of the challenges and charting a path forward.