Each organization in the global community of Crossref members (that’s currently over 24k organizations in 166 different countries) plays a key role in building the Research Nexus. Any opportunity we have to meet with our members in person is a highlight and a way for us to learn more from each other. The month of January saw three of us travel to Bangkok to attend the first-ever Charleston Conference organised in Asia and to meet with our growing community in Thailand.
This year, we placed a spotlight on the Latin American community, hosting the second Crossref Metadata Sprint in São Paulo, Brazil from 4 - 6 March 2026. In our first tri-lingual event, we brought together 31 participants from Argentina, Brazil, Colombia, Ecuador, and Mexico. Our goal was to foster community co-creation using the open scholarly metadata. The Sprint was an opportunity to pose questions, share ideas, collaborate on research, and propose innovative solutions that enhance the use of metadata in scholarly communication and beyond.
Read on for more details about the content of the Sprint, and the resulting projects. You can also register to join our Sprint Showcase call on 22nd April to hear directly from the team about their creations.
On 17 March 2026, we experienced an outage that affected DOI resolution for Crossref DOIs and the deposit of metadata records by Crossref members. In this summary, we outline what happened, the impact on our community, and the steps we are taking to strengthen our systems and processes as a result.
We’re excited to announce a new data citation API endpoint and are seeking your feedback. The new service makes existing data citation relationships in our metadata available, thereby surfacing this part of the research nexus. At the same time, we’ve decided that it’s time to move on from Event Data.
Metadata is communication; it can tell a story about research and paint a picture for others to respond to and learn from, across the world and throughout the forthcoming generations. Metadata can feel technical with words like ‘infrastructure’ and ‘schema’, and sometimes, like tech in general, it comes with hyperbole. But metadata really is part art (storytelling and pictures) and part science (structured models and standards) with both aspects being equally important, and requiring people as well as systems. That necessary combination of human and machine involvement also makes metadata challenging.
Crossref, as the earliest adopter of DOIs specialising in scholarly research, became synonymous with DOIs in this community. However, not everyone realises that DOIs can be registered with any one of nine different agencies, which are all separate organisations with entirely separate systems that do not at present integrate or connect. And what’s more – there isn’t a central or shared “DOI schema” – each agency develops the metadata for the purposes of their organisation or community. In Crossref’s case, with our vision to create the research nexus as a complete and robust network of relationships between objects, people, and institutions of scholarship – that community encompasses the whole of the research enterprise.
The immense 180 million records of research outputs in Crossref are maintained in a system that 24,000 member organisations have already invested in. Those records benefit from rich and format-appropriate metadata schema, developed in close collaboration with the community, which makes it possible for our members to offer contextual information about each object they register. We have a long history of working with our members on recording that context, creating tools, and providing support to adopt standard metadata, enriching the context for the benefit of the scholarly community, and society at large.
Of course, those metadata records are not perfect, both in terms of quality and completeness, and the frustration around gaps in metadata is particularly strong. We are working to improve the quality and completeness of the metadata from many angles: by working with the community to understand their needs and obstacles, by identifying and analysing potential sources for additional metadata, by maintaining and adopting the existing system to changing environment, and by planning a new flexible system that will allow third-party assertions and automated enrichment workflows.
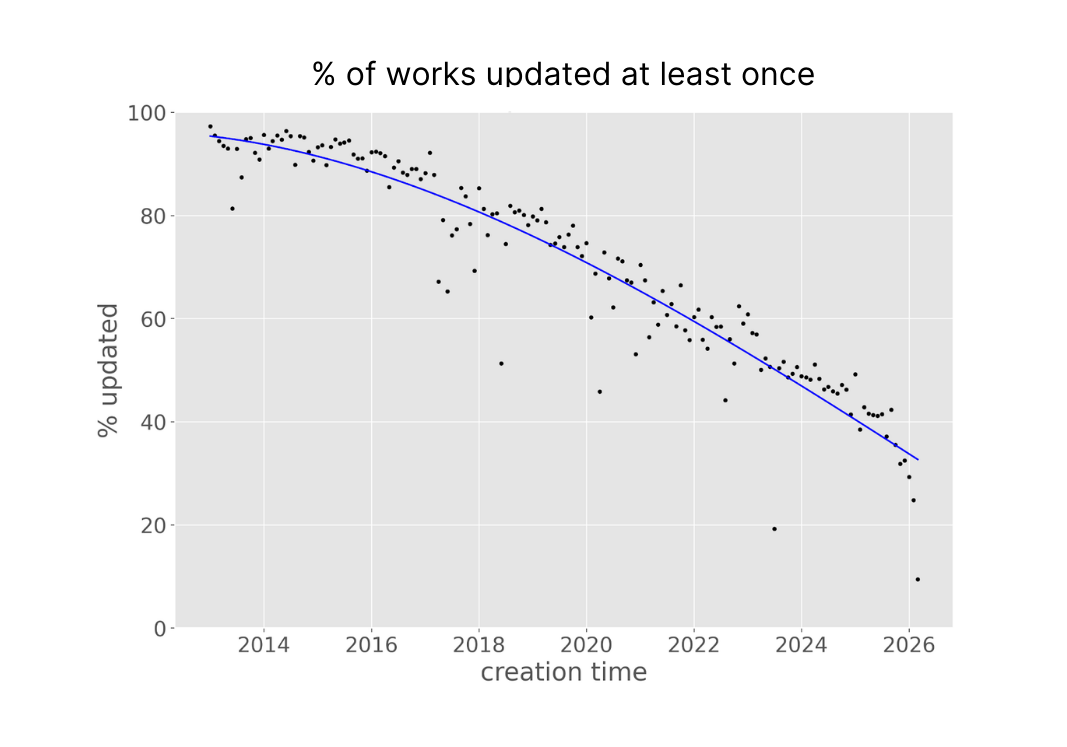
In 2020, we published a paper for the inaugural issue of Quantitative Science Studies on Crossref: The Sustainable Source of Community-Owned Scholarly Metadata and blogged an introduction to it under Crossref Metadata for Bibliometrics. One of the things our analyses in 2019 showed was that over 80% of records between 2013-2016 had been updated. Reviewing the numbers recently, we continue to see this stewardship and maintenance of metadata, amounting to almost 70% of records from the past decade being updated at least once. On the dawn of reaching 2 billion citation links, we’d like to share our experience, plans, and views on this ubiquitous activity of updating and connecting metadata – by our members and by automations built into the system by us. Altogether, these constitute the enrichment process to improve the usability of the information for the community.
Metadata available through Crossref
Crossref collects, processes, stores, and shares metadata records for a wide range of research outputs. While each record describes an individual research output, it also mentions other entities and their attributes - and, most importantly, the relationships between them. Two works identified by DOIs, for example, may be linked by a citation relationship. A person identified by an ORCID may be connected to an institution identified by a ROR ID through an affiliation relationship. A preprint and its corresponding journal article, each with its own DOI, can be linked by an “is preprint of” relationship. A research output may be associated with a grant through a “financed by” relationship. Together, these entities and relationships form the foundational building blocks of the research nexus.
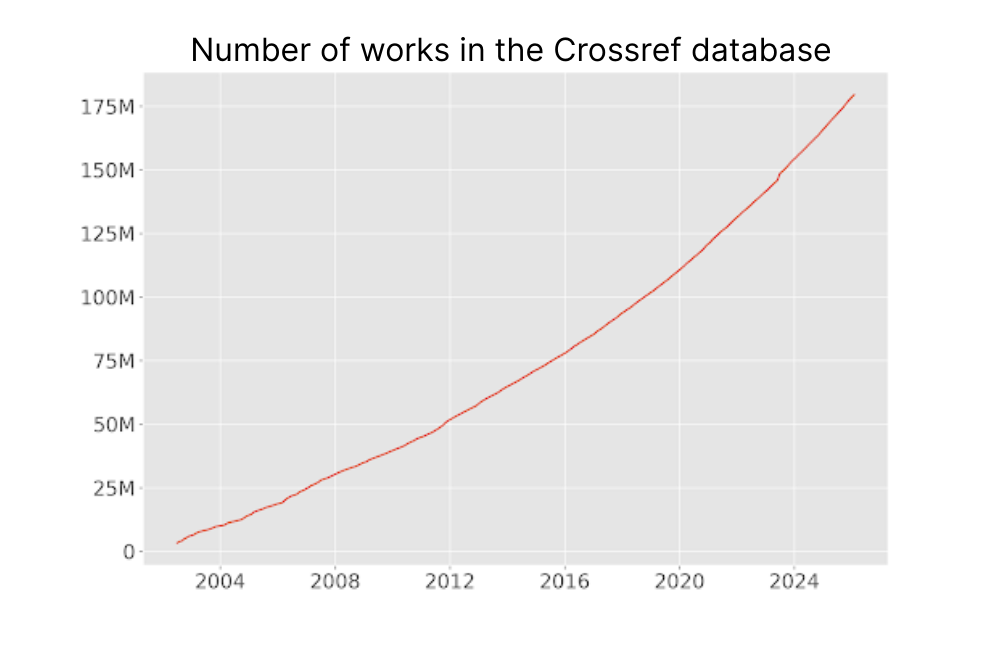
As of March 14, 2026, the Crossref database contains 180,034,490 metadata records describing research outputs. You can download all the records and examine them yourself in the latest public data file. The plot below illustrates how the number of works has changed over time, showing that the rate of growth is accelerating.
The metadata records describe research outputs of various types, including:
journal articles
books and book chapters
conference proceedings
peer reviews
reports
datasets
preprints
dissertations
grants
and more
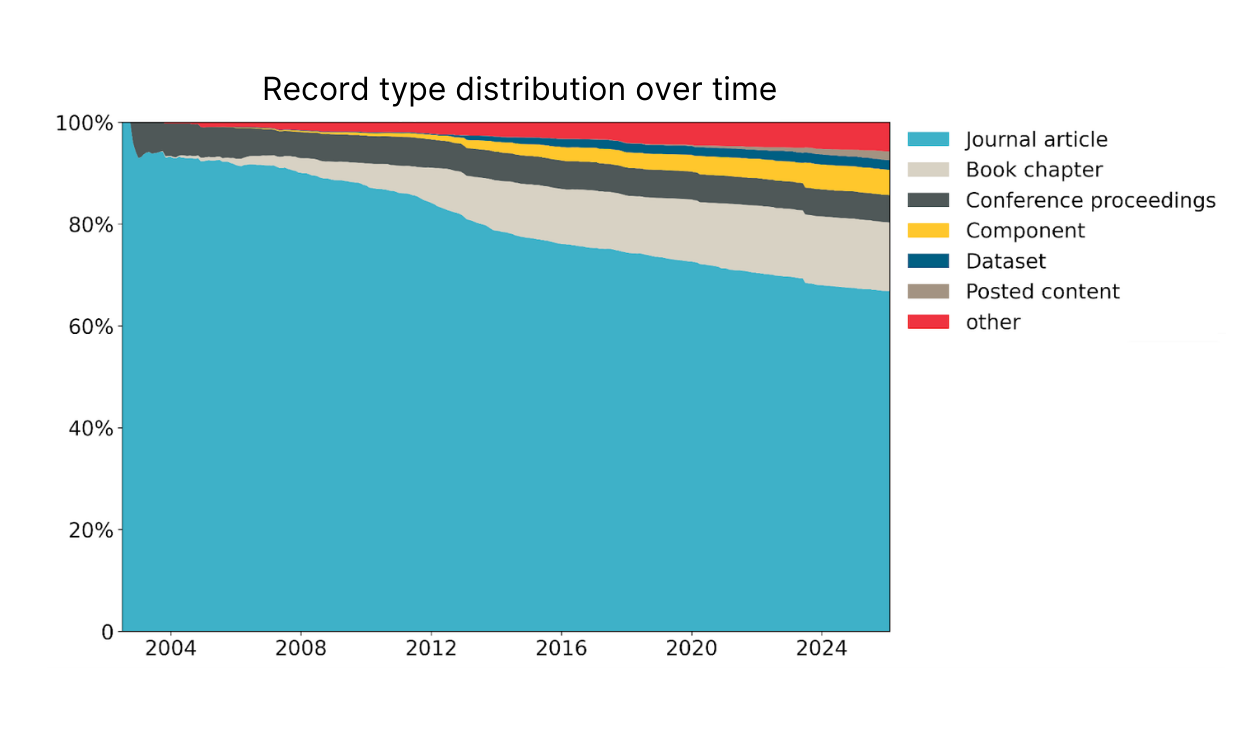
The majority of works in the Crossref database (67%) are journal articles. However, the distribution of record types has changed considerably over time. Newer types, such as components, datasets, and posted content, are growing more quickly than more traditional ways of communicating research:
Research outputs in the Crossref database are represented by rich metadata records, which may include:
funding metadata, including funders and grant details
license metadata
bibliographic reference lists
clinical trial numbers
updates such as corrections or retractions
relationships between works and other entities, such as “is translation of”, “is review of”, “is preprint of”, or “is version of”
components associated with the work, such as figures, tables, and supplemental materials
All metadata is freely available through the Crossref REST API, and additional services, such as Crossref Search, are also provided.
A natural question is: where does all this metadata come from? This is important for two main reasons. First, it helps address the question of trust, as understanding the origin of the metadata allows users to better assess its reliability. Second, it points us to the right place when investigating or addressing issues or gaps in the data.
At first glance, the answer might seem straightforward: from Crossref members. Crossref members, such as publishers, research institutions, universities, funders, museums, libraries, data and subject repositories, and conference providers, register metadata for the outputs they publish. Crossref stores this metadata and makes it available to the community.
In reality, however, the story is more complicated.
Metadata enrichment layers
The initial metadata deposit is only the beginning of what can become a long and rather fascinating journey. What users can see in our REST API is often the result of a series of updates and additions that occur over time, sometimes coming from multiple sources and happening in different ways. We can think of these ways as enrichment layers.
Each enrichment layer offers opportunities to improve the metadata while also introducing its own considerations and challenges. Rather than forming a sequence of clearly separated stages, these layers intertwine, overlap, and affect one another, collectively shaping how a research output is represented within the research nexus.
Enrichment layers are essential for completeness of the research nexus. If we relied solely on the original, one-off deposits from members, the metadata would be full of gaps, limiting the usefulness of any analysis or assessment based on it. While the scholarly metadata will never be perfectly complete, applying these enrichment layers is how we gradually and collectively build a fuller, more accurate picture of the research nexus.
One important caveat is that more metadata doesn’t magically equal better metadata. In fact, there’s often a delicate tradeoff between completeness and quality: the harder one pushes to fill every gap, the greater the chance of introducing errors. At Crossref, we believe quality comes first. We recognise that no dataset will ever be perfect, but we’re equally unwilling to apply enrichment processes without quality control. Any enrichment we introduce must meet a high bar for accuracy — no exceptions, no shortcuts.
The order of the enrichment layers discussed here loosely reflects how established they are within the scholarly ecosystem. There also might be a correlation, or at least a perceived one, between this ordering and the reliability of the underlying processes. That said, one must tread carefully when making such interpretations: perceived reliability is not the same as actual reliability.
Layer 1: Member updates
Crossref members not only deposit metadata, but also update it over time. This is an essential part of the system for several reasons. There may be errors in the originally deposited metadata that need to be corrected. Also, the initial record may contain gaps that can be filled later as more information becomes available. In addition, many changes naturally occur: landing page URLs may change, works may be archived in new locations, or identifiers for affiliated organisations may become available. Those situations also ideally result in an update.
This update process is well established. Over 24,000 Crossref members form a large global community that operates under shared membership terms. As part of these terms, members are responsible for maintaining and updating their metadata records. In this governance framework it is clearly defined who owns and stewards the metadata associated with each record, and who is responsible for the quality level and issues.
Member updates are very common. As an example, over 80% of works deposited between 2013 and 2020 were updated at least once. This demonstrates the community’s commitment to improving completeness and quality of the scholarly record. The plot below shows the percentage of works created in a given month that were updated at least once.
However, this layer also comes with challenges. It relies on members actively meeting their obligations to maintain and improve their metadata. As a result, gaps and inconsistencies can remain, and overall metadata quality is never perfect.
Our plans for the future in this area largely build on what is already happening. This includes developing and maintaining effective user interfaces for updating metadata, evolving the input metadata schema to keep pace with changes in the scholarly landscape, offering regular workshops on metadata improvements, and collaboratively establishing best practices while educating members on how to apply them.
Layer 2: Community feedback loop
Crossref metadata is widely used and examined by a large community of consumers. As a result, issues with metadata are sometimes identified by community members and reported back to us. When this happens, Crossref does not directly correct the metadata records. Instead, we contact the relevant member responsible for the record and able to deposit an update.
In this layer, the stewardship of metadata remains with the member, while responsibility for metadata quality broadens to include other actors in the community. This creates significant potential for scaling by involving a large community in identifying and reporting metadata issues.
At present, however, this process is not automated. Crossref staff effectively act as intermediaries between those reporting issues and the responsible member. As a result, the process has limited scalability. It also depends on the willingness of members to act on the reports they receive, as they are not obligated to respond to such reports.
In the future, we may explore automating portions of this workflow to handle community feedback more efficiently and lighten the load on everyone involved.
Layer 3: Metadata matching
Metadata matching is the task of finding an identifier for an item based on a structured or unstructured description of it. Matching strategies run as fully automated processes that analyse information deposited and updated by members and add identifiers, filling gaps in the metadata.
There are many instances of metadata matching problems, for example:
bibliographic reference matching: finding a DOI for a cited paper based on a bibliographic reference,
funder matching: finding the ROR ID for a funder based on its name,
affiliation matching: finding the ROR ID for an organisation based on an affiliation string,
preprint matching: finding the DOI for a preprint that precedes a given journal article,
grant matching: finding the grant DOI based on an award number and a funder name.
This layer is unique, as it focuses on a crucial type of gap in the scholarly record: the missing relationships between entities. Indeed, adding an identifier for an entity mentioned within a metadata record of a research output is typically an equivalent of asserting a relationship between that output and the matched entity. For example, bibliographic reference matching inserts citation relationships, and funder name matching - funding relationships between a research output and a funding organisation. These relationships form the foundation of the research nexus.
Currently, at Crossref, we perform two types of matching. We match bibliographic references to the DOIs of cited outputs, and funder names to Funder IDs. Both processes rely on fuzzy comparisons and other heuristic approaches to identify likely matches.
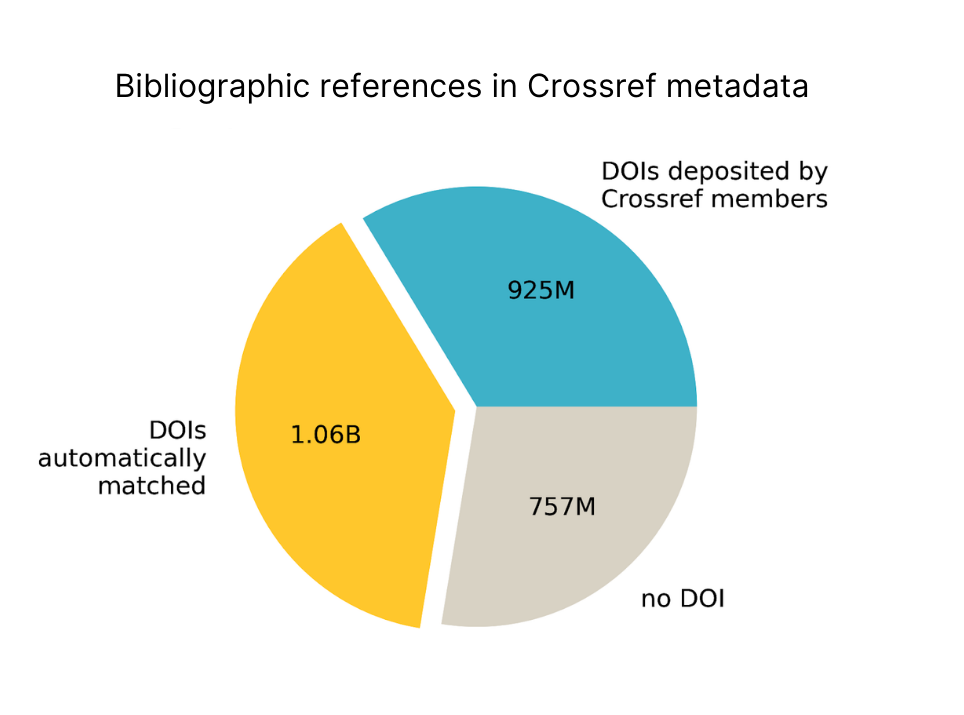
In the case of bibliographic reference matching, as it turns out, more than half of the cited DOIs (1 billion) available in the Crossref database originate from automated metadata matching:
In the case of funder name matching, the distribution is very different, but the matching strategy was still able to fill in some of the gap:
Metadata matching is a particularly valuable form of enrichment for several reasons. Matching strategies can often achieve high levels of accuracy while working in a fully automated way. This makes them highly scalable and drastically reduces the need for human oversight. Their focus on relationships also strengthens the foundations of the research nexus.
At the same time, this enrichment layer presents a number of challenges.
Its most fundamental limitation to remember is that metadata matching can only fill gaps when there is at least some useful information to work with. For example, it can identify a cited document only using structured or unstructured citation data, and the funding organisation can only be identified if some funding information is available. But if citation information, or funding information, is completely absent, as is the case for 101M (56%) records and 166M (92%) records respectively, then matching simply isn’t possible.
Perhaps most importantly, in the case of matching, it becomes less clear who is responsible for the information introduced through the matching process. This is particularly important because matching results are never perfect, meaning there is always a risk of introducing errors. The risk is further amplified by the fact that matching strategies typically operate in a fully automated, unsupervised manner. As a result, careful evaluation of matching performance, as well as maintaining accurate provenance records, becomes increasingly important.
At Crossref, we have ambitious plans in this area. We intend to rebuild Crossref’s metadata matching workflows using modern software development and data science practices. The goal is to create a dedicated, consolidated matching service that will eventually replace all existing production matching processes, with results made available through the REST API. This project will cover six matching tasks: bibliographic reference matching, funder name matching, preprint matching, affiliation matching, grant matching, and title matching. You can learn more about metadata matching at Crossref at a dedicated project page.
Layer 4: Third-party datasets
There are many databases containing scholarly data, and one way to fill gaps in Crossref member-provided metadata is to incorporate additional metadata from those external sources.
We already have one example of this. Crossref ingests data from the Retraction Watch database to supplement information about retractions and other updates to records:
This layer has several advantages. It draws on subject-specific and metadata-specific expertise, avoids reinventing work that has already been done elsewhere, and reflects a collaborative community-driven approach to improving the scholarly record.
However, there are also important challenges to consider. Integrating external data often involves multiple data licenses or acquisition arrangements, and there may be less control over data quality compared to metadata that comes directly from members. There is also a risk that relying too heavily on external sources could shift responsibility away from the member stewards of the metadata. Finally, it can be difficult to determine which external datasets provide sufficient value and longevity to justify long-term integration.
Looking ahead, we plan to explore further opportunities to incorporate third-party datasets, carefully considering the value they bring, as well as issues of licensing, sustainability, and data quality.
Layer 5: Unstructured content scraping
A significant amount of scholarly information still exists in fully unstructured forms, such as full-text PDF documents and web pages. In principle, extracting information from these sources could help fill many gaps in existing metadata.
In a lighter-touch approach, analysing full-text documents can also help verify existing metadata elements. If such a check fails, the unverified element may be removed from the record — which, perhaps counterintuitively, can also count as enrichment, since improving accuracy is every bit as important as adding new information.
There are also important challenges to consider. Extracting metadata directly from unstructured sources could substantially shift responsibility away from the original data stewards or owners, weakening the current stewardship model. The results of automated extraction may also be inconsistent or of relatively low quality. In addition, there are potential legal and rights-related concerns, particularly when processing full-text materials. Finally, developing reliable extraction methods would require substantial research and engineering effort.
For all these reasons, the practical usefulness of this approach remains uncertain, and Crossref currently has no plans to run such processes in production. We will, however, keep a close eye on emerging extraction technologies and may consider adopting them in some form if future evaluations show clear value.
Summary
Metadata is far more than a technical afterthought of the publishing process. It is the connective tissue of the scholarly ecosystem, linking research objects, people, and institutions into a coherent, navigable network. At Crossref, this takes the form of a vast and continually evolving corpus of more than 180 million metadata records, all contributing to the emerging research nexus, being built through collective community effort to help the global research community discover, interpret, and reuse knowledge effectively.
The initial metadata record deposited by members is only the beginning. Its quality and completeness can improve over time through multiple enrichment layers: member-driven updates, community feedback, automated metadata matching, and the incorporation of third-party datasets. These processes help fill gaps and strengthen the reliability of the scholarly record, all while upholding a firm commitment to accuracy and stewardship.
Taken together, these layers reflect a long-term, collaborative effort across technology developments, community participation, and responsible automation, to ensure that scholarly metadata becomes richer, more interconnected, and more useful for everyone who relies on it.