Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, and this is changing now.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
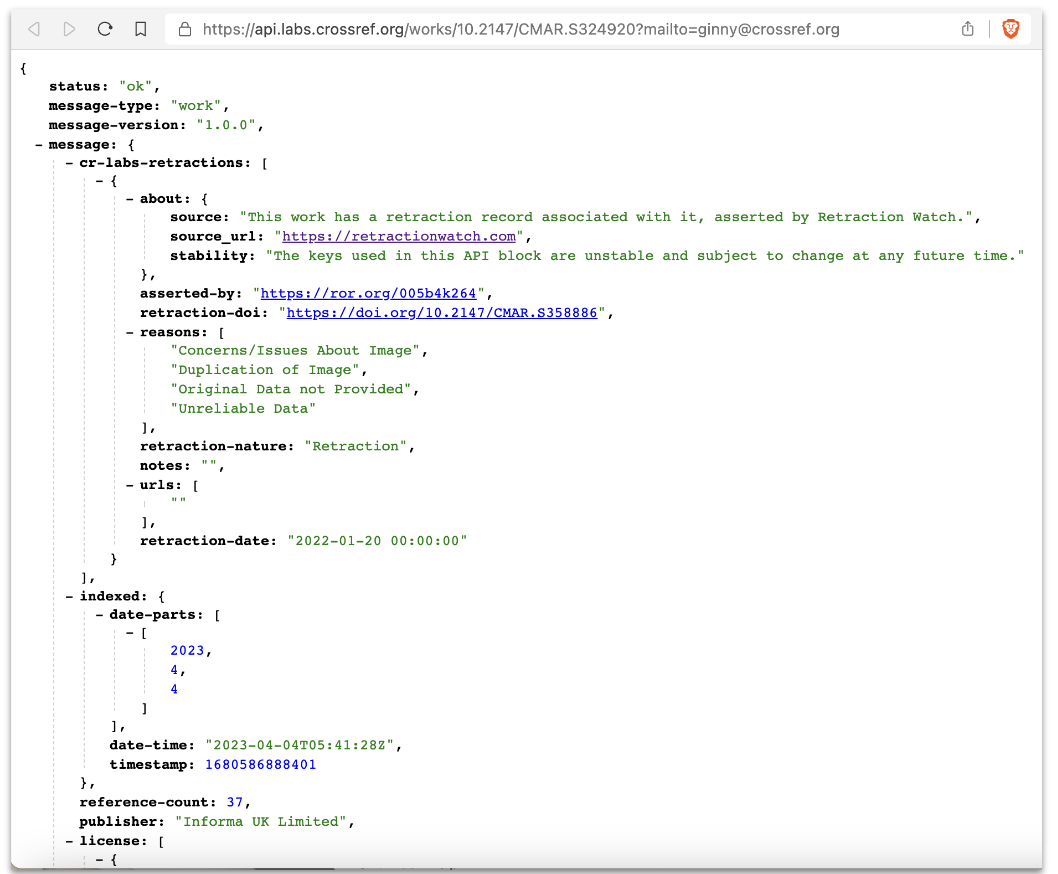
Crossref acquires Retraction Watch data and opens it for the scientific community
Agreement to combine and publicly distribute data about tens of thousands of retracted research papers, and grow the service together
12th September 2023 —– The Center for Scientific Integrity, the organisation behind the Retraction Watch blog and database, and Crossref, the global infrastructure underpinning research communications, both not-for-profits, announced today that the Retraction Watch database has been acquired by Crossref and made a public resource. An agreement between the two organisations will allow Retraction Watch to keep the data populated on an ongoing basis and always open, alongside publishers registering their retraction notices directly with Crossref.
Both organisations have a shared mission to make it easier to assess the trustworthiness of scholarly outputs. Retractions are an important part of science and scholarship regulating themselves and are a sign that academic publishing is doing its job. But there are more journals and papers than ever, so identifying and tracking retracted papers has become much harder for publishers and readers. That, in turn, makes it difficult for readers and authors to know whether they are reading or citing work that has been retracted. Combining efforts to create the largest single open-source database of retractions reduces duplication, making it more efficient, transparent, and accessible for all.
Product Director Rachael Lammey says, “Crossref is focused on documenting and clarifying the scholarly record in an open and scalable form. For a decade, our members have been recording corrections and retractions through our infrastructure, and incorporating the Crossmark button to alert readers. Collaborating with Retraction Watch augments publisher efforts by filling in critical gaps in our coverage, helps the downstream services that rely on high-quality, open data about retractions, and ultimately directly benefits the research community.”
The Center for Scientific Integrity and the Retraction Watch blog will remain separate from Crossref and will continue their journalistic work investigating retractions and related issues; the agreement with Crossref is confined to the database only and Crossref itself remains a neutral facilitator in efforts to assess the quality of scientific works. Both organisations consider publishers to be the primary stewards of the scholarly record and they are encouraged to continue to add retractions to their Crossref metadata as a priority.
“Retraction Watch has always worked to make our highly comprehensive and accurate retraction data available to as many people as possible. We are deeply grateful to the foundations, individuals, and members of the publishing services industry who have supported our efforts and laid the groundwork for this development,” said Ivan Oransky, executive director of the Center for Scientific Integrity and co-founder of Retraction Watch. “This agreement means that the Retraction Watch Database has sustainable funding to allow its work to continue and improve.”
Please join Crossref and Retraction Watch leadership, among other special guests, for a community call on 27th September at 1 p.m. UTC to discuss this new development in the pursuit of research integrity.
Supporting details
Crossref retractions number 14k, and the Retraction Watch database currently numbers 43k. There is some overlap, making a total of around 50k retractions.
Crossref is paying an initial acquisition fee of USD $175,000 and will pay Retraction Watch USD $120,000 each year, increasing by 5% each year.
The initial term of the contract is five years. The full text of the contract will be made public in the coming fortnight.EDIT 2023-09-26:Here is the signed agreement.
There will be a community call on 27th September at 1 p.m. UTC (your time zone here). Please register.
An open FAQ document is available to collect questions to be answered at the webinar.
About Retraction Watch and The Center for Scientific Integrity
The Center for Scientific Integrity is a U.S. 501(c)3 non-profit whose mission is to promote transparency and integrity in science and scientific publishing, and to disseminate best practices and increase efficiency in science. In addition to maintaining and curating the Retraction Watch Database, the Center is the home of Retraction Watch, a blog founded in 2010 that reports on scholarly retractions and related issues in research integrity.
About Crossref
Crossref is a global community infrastructure that makes all kinds of research objects easy to find, assess, and reuse through a number of services critical to research communications, including an open metadata API that sees over 2 billion queries every month. Crossref’s >19,000 members come from 151 countries and are predominantly university-based. Their ~150 million DOI records contribute to the collective vision of a rich and reusable open network of relationships connecting research organisations, people, things, and actions; a scholarly record that the global community can build on forever, for the benefit of society.