Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
Quality metadata is foundational to the research nexus and all Crossref services. When inaccuracies creep in, these create problems that get compounded down the line. No wonder that reports of metadata errors from authors, members, and other metadata users are some of the most common messages we receive into the technical support team (we encourage you to continue to report these metadata errors).
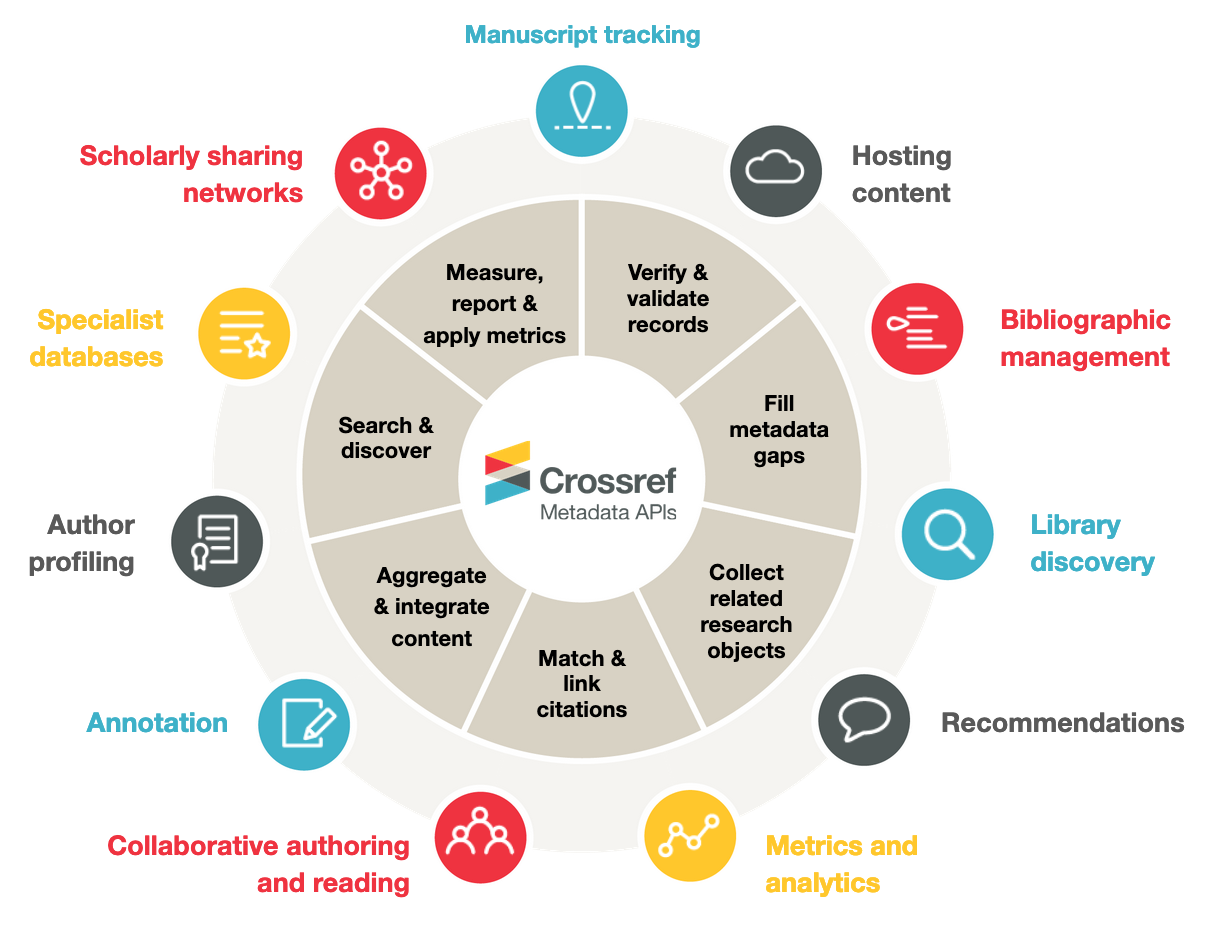
We make members’ metadata openly available via our APIs, which means people and machines can incorporate it into their research tools and services - thus, we all want it to be accurate. Manuscript tracking services, search services, bibliographic management software, library systems, author profiling tools, specialist subject databases, scholarly sharing networks - all of these (and more) incorporate scholarly metadata into their software and services. They use our APIs to help them get the most complete, up-to-date set of metadata from all of our publisher members. And of course, members themselves are able to use our free APIs too (and often do; our members account for the vast majority of overall metadata usage).
We know many organisations use Crossref metadata. We highlighted several different examples in our API case study blog series and user stories. Now, consider how errors could be (and often are) amplified throughout the whole research ecosystem.
While many inaccuracies in the metadata have clear consequences (e.g., if an author’s name is misspelled or their ORCID iD is registered with a typo, the ability to credit the author with their work can be compromised), there are others, like this example of typos in the publication date, that may seem subtle, but also have repercussions. When we receive reports of metadata quality inaccuracies, we review the claims and work to connect metadata users with our members to investigate and then correct those inaccuracies.
Thus, while Crossref does not update, edit, or correct publisher-provided metadata directly, we do work to enrich and improve the scholarly record, a goal we’re always striving for. Let’s look at a few common examples and how to avoid them.
Very little content begins and ends on page 1. Especially journal articles. But, many members may not know what the page range of the content will be when they register the content with us (perhaps the content in question is an ahead-of-print journal article and the member intends to update this page range later). The issue here is that page range is an important piece of the metadata that we use for citation matching. If the pagination registered with us is incorrect, and it differs from the pagination stated in the citation, our matching process is challenged. Thus, we might fail to establish a citation link between the two works. The page range beginning with page 1 is the most common pagination error that the technical support team sees.
Like first pages beginning with 1, few internal article numbers are 1. We see a disproportionate number of article number 1s in the metadata. Again, this can prevent citation matching. Mistakes happen in all aspects of life, including metadata entry. That said, if you, as a member, don’t use internal article numbers or other metadata elements that can be registered, a recommendation we’d make is: if you don’t know what the metadata element is, omit it. More metadata does not mean better metadata. If you’d like to know more about what the elements are, bookmark our schema documentation in Oxygen or review our sample XML files.
This content either begins on page 121, 122, or 123. It cannot start on all three pages. Ironically, registering a first page of 121-123 ensures that we will not match the article if it is included in a citation for another DOI with a first page of 121, 122, or 123.
Author naming lapses
Examples: Titles (Dr., Prof. etc.) in the given_name field; Suffixes (Jr., III, etc.) in the surname field; superscript number, asterisk, or dagger after author names (usually carried over from website formatting that references affiliations); full name in surname field
<contributors><person_namecontributor_role="author"sequence="first"><surname>Mahmoud Rizk</surname></person_name><person_namecontributor_role="author"sequence="additional"><surname>Asta L Andersen(</surname></person_name></contributors>
Neither Josiah nor Kathryn’s official given name includes ‘doctor,’ thus it should be omitted from the metadata. Including ‘doctor’ in the metadata and/or capping the authors’ names in the metadata does not result in additional accreditation or convey status. Instead, the result is to muddle the metadata record. As with page numbers in the metadata, accurate author names are crucial for citation matching.
organisations as authors slip-ups
Examples: The contributor role for person names is for persons, not organisational contributors, but we see this violated from time to time. Unfortunately, no persons are being credited with contributing to content that have these errors present in the metadata record.
<person_namecontributor_role="author"sequence="first"><given_name>University of Melbourne</given_name><surname>University of Melbourne</surname></person_name></contributors>
We love seeing inclusion of organisational contributors in the metadata, when that metadata is correct. Unfortunately, we do see mistakes where organisations are entered as people and people are inadvertently omitted from the metadata record (sometimes omission of people in the contributor list is intentional, but other times it is a mistake). In the XML above, the organisation was entered as an organisational contributor - the organisation itself is being credited with the work. This is sometimes confused with an author affiliation or even a ROR ID. Our schema library and XML samples are a great place to start, if you’re interested in learning more about organisational contributors versus author affiliations.
Null no-nos
Examples: Too many times we see “N/A”, “null”, “none” in various fields
(pages, authors, volume/issue numbers, titles, etc.). If you don’t have or know the metadata, it’s better to omit it for optional metadata elements than to include inaccuracies in the metadata record.
Nulls and Not Availables, like many of the examples in this blog, are not simply agnostic when included in the metadata record. Including nulls in your metadata limits our ability to match references and establish connections between research works. These works do not expand and enrich the research nexus; quite the opposite. The incorrect metadata limits our ability to establish relationships between works.
Where to go from here?
One thing we’ve said throughout this blog that we’ll reiterate here is: accurate metadata is important. It’s important in itself, and the metadata registered with us is heavily used by many systems and services, so think Crossref and beyond. In addition to that expanding perspective, there are practical steps members and metadata users can take to help us:
As a member registering metadata with us:
make sure we have a current metadata quality contact for your account and update us if there’s a change
if you receive an email request from us to investigate a potential metadata error, help us
if you do not know what to enter into a metadata element or helper tool field, please leave it blank; perhaps some of the examples of errors within this blog were placeholders that the responsible members intended to come back to - to correct in time; that’s also a practice to avoid
if you find a record in need of an update, update it - updates to existing records are always free (we do this to encourage updates and the resulting accurate, rich metadata, so take advantage of it).
As a metadata user:
if you spot a metadata record that doesn’t seem right, let us know with an email to support@crossref.org and/or report it to the member responsible for maintaining the metadata record (if you have a good contact there)
Making connections between research objects is critical, and inaccurate metadata complicates that process. We’re continually working to better understand this, too. That’s why we’re currently researching the reach and effects of metadata. Our technical support team is always eager to assist in correcting errors. We’re also keen on avoiding those mistakes altogether, so if you are uncertain about a metadata element or have questions about anything included in this blog post, please do contact us at support@crossref.org. Or, better yet, post your question in the community forum so all members and users can benefit from the exchange. If you have a question, chances are others do as well.