PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Test out the early preview of Event Data while we continue to develop it. Share your thoughts. And be warned: we may break a few eggs from time to time!
Chicken by anbileru adaleru from the The Noun Project
Want to discover which research works are being shared, liked and commented on? What about the number of times a scholarly item is referenced? Starting today, you can whet your appetite with an early preview of the forthcoming Crossref Event Data service. We invite you to start exploring the activity of DOIs as they permeate and interact with the world after publication.
But first, a bit of background
Discussion around scholarly research increasingly occurs online after publication, for example on blogs, sharing services, social media, and wikis. These ‘events’ occur across the web on numerous platforms and are a critical part of the scholarly enterprise. We are developing an infrastructure service (Crossref Event Data) that collects, stores, and delivers raw data of the events occurring with Crossref DOIs. We will store the data in an open, auditable and portable form for the community to access. Publishers, platforms, funders, bibliometricians and service providers may benefit from access to this raw data, and it can be used to feed into research records or proprietary tools and services that offer aggregation and analysis.
Developers Martin Fenner (DataCite) and Joe Wass (Crossref) enjoy a tofu break
Lagotto, the software originally developed at PLOS, has been extended and improved in a joint effort between DataCite and Crossref. The two DOI Registration Agencies have partnered to envision, build and release the service. On the 13th of April, after a year ofcollaboration, we jointly released Lagotto 5.0. You can read about the collaboration on the DataCite blog post.
Crossref and DataCite will continue to work closely together to develop Lagotto and the Event Data service. Although Crossref Event Data has mostly Crossref DOIs at launch, you will be able to find DataCite DOIs if they are cited in Crossref or Wikipedia.
All of the software that runs Event Data, including Lagotto, is developed in the open and is open source. Please refer to the Crossref Event Data Technical User Guide for full details.
Preview the data
This service is currently under development with a full launch expected the second half of 2016. Before it is launched however, we invite you to take a look around and preview a subset of the data sources we plan to include. You may experience occasional hiccups while we continue building the service.
At this stage, we are working with data from three sources although we will greatly expand the variety of platforms from which we collect data as development progresses. At this stage, you can view Mendeley bookmarks, Wikipedia references, and Crossref to DataCite links.
Mendeley
Mendeley is a reference manager and academic social network for scholars. View the number of social bookmarks from scholars or groups on Mendeley.
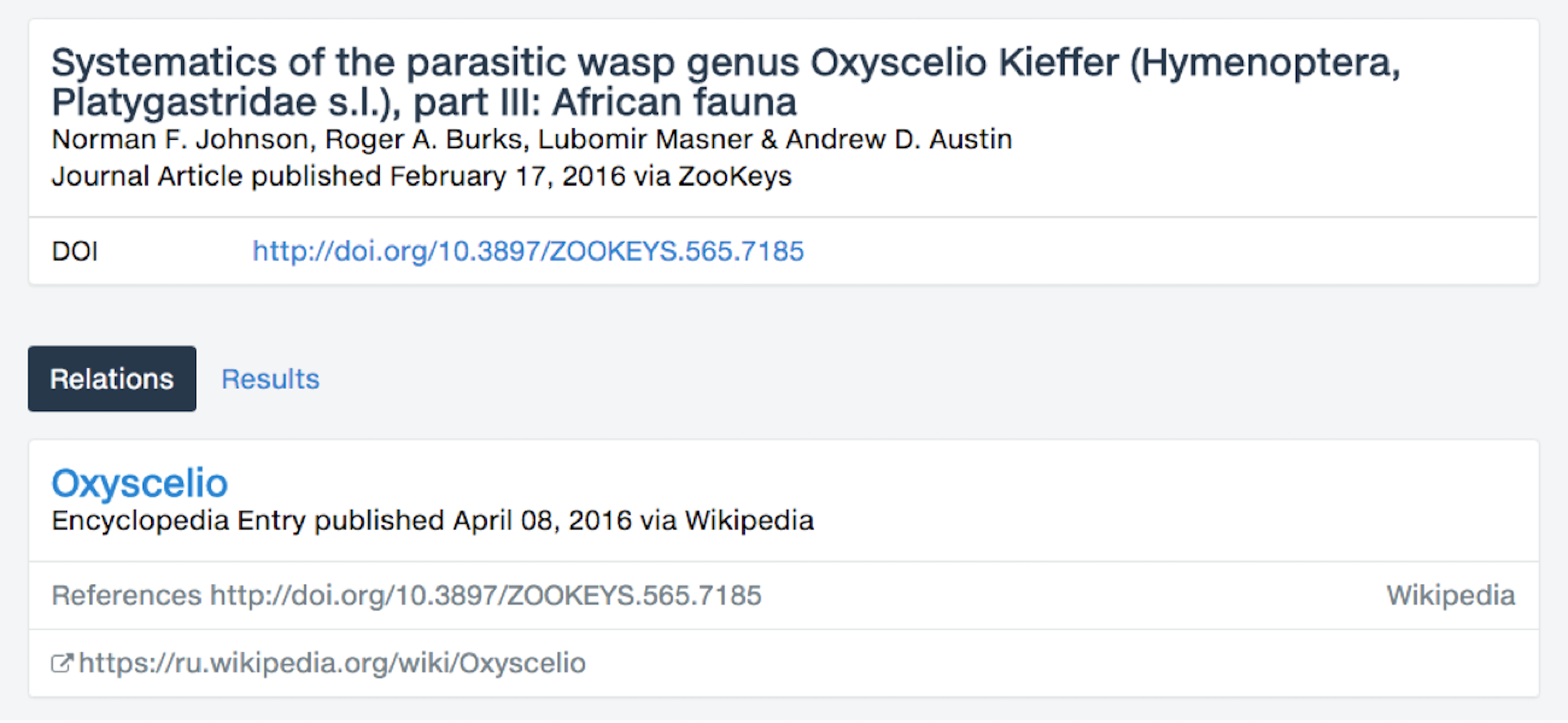
Wikipedia is an online encyclopaedia, the Internet’s largest and most popular general reference work. View references in Wikipedia of Crossref publications in Wikipedia articles in all languages.
DataCite is a global consortium that assigns DOIs to research data. This enables people to find, share, use, and cite data. You can view all the data citations to DataCite research outputs found in Crossref publications (work is underway to make the links found in DataCite metadata available in Event Data).
This service is currently under development and as such we welcome your thoughts and feedback on the data we are collecting currently from our three active sources. As a reminder, we expect to include the following sources as part of our full service launch later this year (pending confirmation):
[table id=1 /]
We’re also on the lookout for new data sources to investigate for future inclusion in the Event Data service so please do get in touch with requests and recommendations. As we continue to build the service throughout 2016, we will be committing to a model of continuous development so that we can make new sources available as they are completed.
Watch this blog for regular updates on our progress, or subscribe to receive new blog posts by email (just add your details to the upper right side of this page).