6 minute read.Crossing the Rubicon - The case for making chapters visible
To help better support the discovery, sale and analysis of books, Jennifer Kemp from Crossref and Mike Taylor from Digital Science, present seven reasons why publishers should collect chapter-level metadata.
Book publishers should have been in the best possible position to take advantage of the movement of scholarly publishing to the internet. After all, they have behind them an extraordinary legacy of creating and distributing data about books: the metadata that supports discovery, sales and analysis.
Librarianship, and the management of book catalogs at scale took off in the nineteenth century. The Dewey Decimal Classification, the various initiatives of the Library of Congress and the British Library followed. Innovations from the 1960s gave us MARC records and ISBNs. The late 90s produced ONIX, which gave the book industry a tremendous start in migrating online.
However, progress in the decades after appears to have been less dramatic. Some might even argue that this tremendous legacy and wealth of metadata experience has acted as a weight, and has slowed progress. Nowhere is this lack of progress clearer than in the discovery and analysis of book chapters: approximately one-quarter of books published per year has chapter-level metadata, and about two-thirds of books don’t have a persistent and open identifier, ratios that have not significantly changed over the last ten years.
Only one-quarter of scholarly books make chapter level metadata available
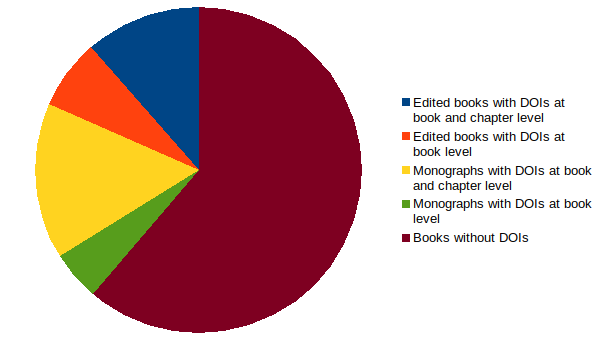
The proportion of edited books and monographs with chapter-level data is approximately one-quarter of all books published in the last ten years. Calculating this figure is necessarily approximate, using numbers published in Grimme et al (2019), and based on data and observed trends in both Dimensions and Crossref.
So why the lack of progress?
For many publishers and their vendor partners, with systems geared up to the efficient delivery of title-level information, the case for moving towards chapter-level metadata can seem daunting (and potentially expensive!).
Metadata is necessarily detailed and it’s not the kind of thing most people will dabble in. Practitioners, as in other technical fields, have expertise that others may find difficult to leverage if they don’t know what questions to ask. organisations often find themselves entrenched in outdated approaches to metadata.
Crossref and Metadata 2020 are collaborating to produce arguments why publishers should move from book-level metadata to chapters. They’ve been working with representatives from the scholarly community, including both small and large presses, not-for-profits and university presses.
1. Increased discoverability
Increasingly, we’re seeing students and researchers move away from traditional book catalogs and onto more general purpose tools, that are often optimized for journal content, and which may - inadvertently - exclude books and chapters from search results. Making chapter level data and DOIs available places book content into these new channels at no additional cost, and starts to reduce the dependency on specialist vendors. Discovery is simplified, requiring less familiarity or expertise to find relevant book content.
2. Increased usage
Exposing the contents of books at a more granular level drives more users towards the book content, and increasing usage numbers and (depending on platform and business model) revenue.
3. Matching author expectations
New generations of authors expect their content to be easily discoverable in the platforms they use. Without chapter level data, this content won’t easily be found in Google Scholar, Mendeley or ResearchGate. For younger researchers, for those in certain disciplines or using resources well-suited to it, if the chapter metadata - which in many cases requires either an introductory paragraph or an abstract - is missing, the book may as well not exist.
4. Author exposure
About half of scholarly book publishing is thought to be in the form of collected works: books where two or three editors get credit at the top level, but dozens of authors contribute to the chapters. Without chapter level metadata, these authors – the book authors of tomorrow – get no credit for their efforts.
5. Usage and citations reporting
Having chapters readily available in the modern platforms means that they start to accumulate evidence of sharing and citations from the moment of being published. Where chapter content is available on its own, the lack of associated metadata inhibits this evidence. After all, the DOI is a citation identifier. Evidence of impact is now critical for research evaluation, funding, tenure and promotion, and without this data, an author’s chapter may as well remain unread.
6. Supporting your authors with funding compliance and reporting
Authors are increasingly being mandated by their funders to report back on the status of their books and chapters. And, in the case of Open Books and Open Chapters, the funders and authors are frequently the ultimate clients, who are looking to record and report evidence of both academic or social impact. Making chapter level information and identifiers available will facilitate this evidence gathering, especially for open chapters within otherwise non-open books, and increasingly common phenomena.
7. Understanding the hot topics in your books
Whether you use Altmetric, or one of the other data sources that capture book activity, being able to access the social and media metrics of the chapters in your book gives you an immediate insight into the topics that capture interest at a broader level. Vital information when it comes to planning more books in the space, especially if you’re on the look out for books with trade crossover potential.
With chapter-level data, publishers can summarize their programs and compare how many authors they work with, how many book titles they have and where there might be gaps in subject and authors omitted from the metadata. Does the scholarly record fully reflect each book? If not, there may be a good deal of information that is simply unavailable to the machines that read the metadata and use it in systems throughout scholarly communications.
Fortunately, it’s becoming easier to manage this data. Although traditional book metadata systems don’t always support chapter-level data, they do often permit publishers to register title-level DOIs, and with Crossref encouraging ISBN information alongside the generation of chapter level DOIs, some of the significant challenges have been reduced.
Both Crossref and Metadata 2020 offer best practices that make clear the need for richer metadata. It’s also important to acknowledge the very real barriers to providing robust metadata, whether for book chapters or anything else, which is why having the conversations and being aware of available resources is important. Because, though it may be difficult, the hurdles are often up-front making the decision to invest in better metadata, factoring in associated costs, setting up workflows, etc.
But as we have seen from the previous decades, book publishers and their suppliers are experts in managing substantial amounts of metadata. Just as no-one would argue to roll-back all those advantages, we believe that - once deployed - industry-wide creation and distribution of chapter data would be an advance from which there is no retreat.
REFERENCES
https://riojournal.com/article/38698/
The State of Open Monographs Report
https://longleafservices.org/blog/the-sustainable-history-monograph-pilot/
https://scholarlykitchen.sspnet.org/2017/12/07/enriching-metadata-is-marketing/
https://www-ingenta-com.turing.library.northwestern.edu/blog-article/five-reasons-chapter-level-metadata-increases-value-academic-books/




